
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 데이터분석
- LLM
- 코딩테스트
- Lora
- 프로그래머스
- 머신러닝
- Coursera
- Generative AI
- speaking
- bfs/dfs
- 파인튜닝
- 알고리즘
- 코딩테스트실력진단
- 최단경로
- 플로이드와샬
- Python
- 코드트리
- 파이썬
- 그래프이론
- Study
- 스터디
- peft
- English
- Fine-Tuning
- DP
- Scaling Laws
- 완전탐색
- paper review
- 이분탐색
- 판다스
- Today
- Total
생각하는 아져씨
[Coursera] Generative AI - Introduction to LLMs 본문
[Coursera] Generative AI - Introduction to LLMs
azeomi 2023. 8. 2. 15:15앤드류 응 교수님의 강의를 듣고 정리한 글임을 알려드립니다.
Generative AI with LLMs
In Generative AI with Large Language Models (LLMs), created in partnership with AWS, you’ll learn the fundamentals of how generative AI works, and how to deploy it in real-world applications.
Week 1주차 초반을 듣고 있는데 아직까지는 자세한 내용보다는 제목처럼 Introduction의 느낌이 강합니다.
Week 2 까지는 들어봐야 어떤 분들에게 도움이 되는 강의일 지 생각할 수 있을 것 같네요😉
강의를 듣고 간략하게 정리한 내용을 적었습니다.
LLMs 은 어디에 사용하고 있을까?
Generative AI와 LLMs는 챗봇에 focused 되어 있다고 생각할 수 있는데요,
챗봇 뿐만 아니라 다양한 Task를 동작하는데에는 Next Word Prediction 개념이 base로 깔려있습니다.
이 개념으로 Text Generation 내에서 동작하는 다양한 Task에 LLMs & Generative AI를 활용할 수 있는 것입니다.
현재까지 LLM는 다음과 같은 Task에 활용할 수 있습니다.
- Write an Essay with prompts
- Summary
- Translate
- CodeAI(Natural Language → Machine Code)
- Entity Extraction(Named entity recognition, word classification의 종류)
여기에 External data 또는 External API 까지 활용하면, LLM의 기능을 더욱 증대시킬 수 있습니다.
Augmenting LLMs → your model to power interactions with the real-words!
Transformer 이전의 문장 생성은 어땠을까?
요즘 LLMs 인 Generative AI의 생성 알고리즘은 최신이 아니다!
모두가 알다시피, 요즘 LLMs의 베이스는 바로 트랜스포머 입니다.
트랜스포머 이전의 생성 알고리즘에는 RNN이 있었습니다.
RNN (Recurrent Neural Network)
강력했지만,
- were limited by the amount of compute
- and memory needed to perform well at generative tasks
- _ _ _ _ _ word 1
- _ _ _ _ word2 word1
1번보다 2번이 previous word를 더 많이 봐서 잘 동작하지만, 앞단어를 더 보려면 모델은 Scaled 되어야 한다는 문제가 있었습니다.
It still hasn’t seen enough of the input to make good prediction
모델이 확장되어도 여전히 RNN은 좋은 예측을 만들지 못했죠
Next word를 잘 예측하려면?!
그렇다면, 다음 단어를 더 잘 예측하려면 어떤 조건이 필요할까요?
- 더 많은 previous word를 봐야한다.
- 전체 문장 또는 전체 문서 속의 이해가 있어야 한다.
- 문장 속 ‘단어’는 다양한 의미를 가지고 있으니 이를 고려해야 한다. → syntactic ambiguity
이 중 세번째가 가장 중요한 것 같습니다. 다음 문장에서 선생님이 학생을 책으로 가르쳤다는 것인지 그 책이 학생이 가지고 있는 것이라는 것인지 헷갈립니다.
“The teacher taught the students with the book”
어떻게 기계가 이런 문장을 잘 이해할 수 있을까요?!
인간의 언어를 더 잘 이해하는 Transformer 등장
2017년 Attention is all you need라는 제목으로 유명한 논문이 나왔습니다.
최신 LLMs의 베이스가 되는 트랜스포머 모델은 다음의 장점을 가지고 있고 이 장점으로 RNN의 한계점을 보완할 수 있었죠!
- Scaled Efficiently : 멀티 GPU를 활용해 확장 가능
- Parallel Process : input data에 parallel process 가능으로 많은 데이터셋 활용
- Attention to input meaning : 문장의 의미를 더 잘 이해
## Transformer의 아키텍처 맛보기
트랜스포머,
RNN을 넘어서는 성능으로 “Led to an explosion in regenerative capability”
트랜스포머가 강력하게 동작하는 파워는 바로, 이것입니다.
Ability to learn the relevance and context of all of the words in a sentence
그 주인공에는 바로 Self Attention이 있죠!
아키텍쳐
2017년 논문에 나와있는 트랜스포머의 아키텍쳐 그림을 간단히 그리면 이렇게 생겼습니다.
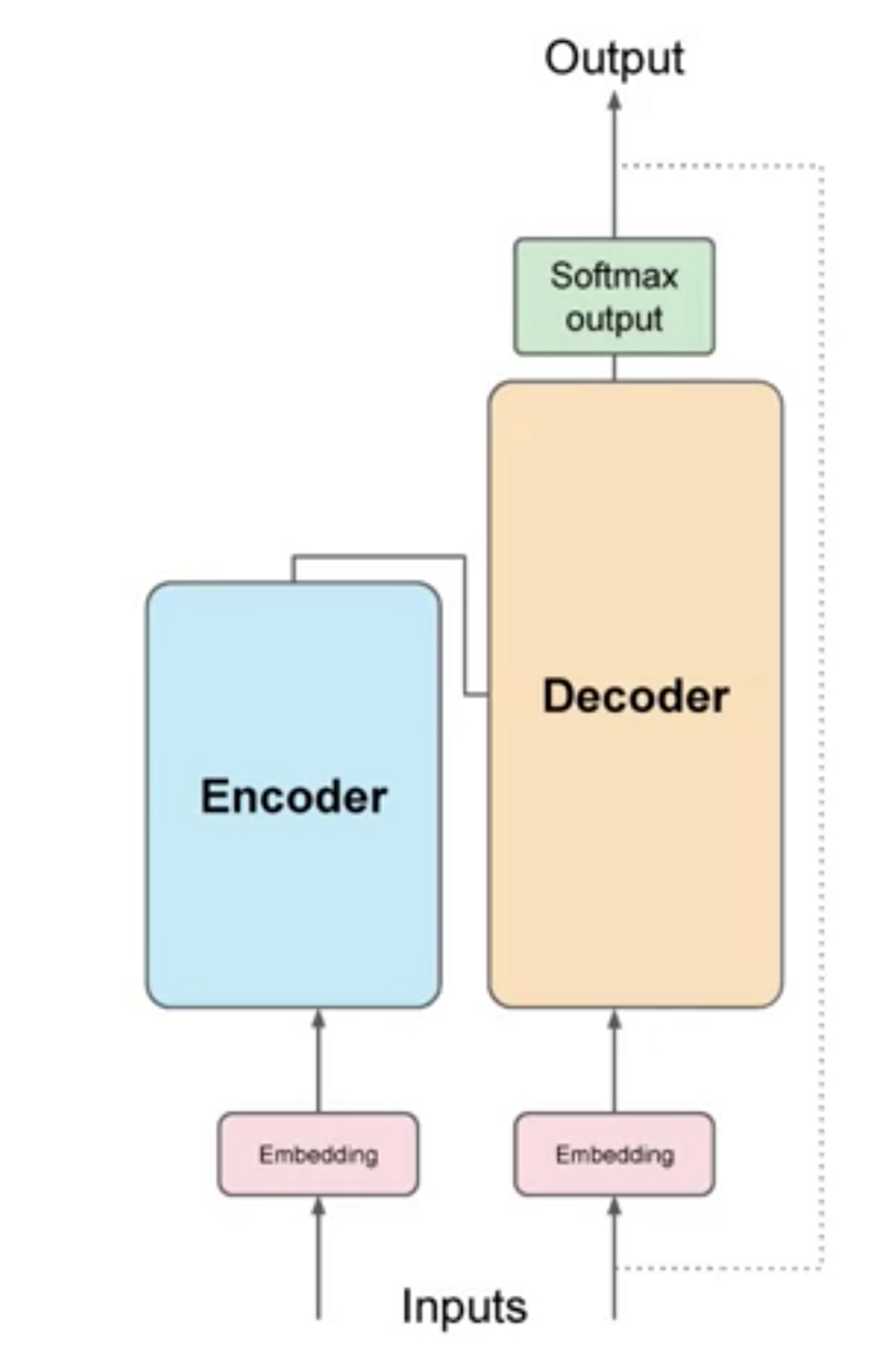
강의에서 가져온 그림입니다.
인코더와 디코더가 존재하고, 아래로 Input이 들어가면 위로 Output이 나오는 형태입니다.
Big Statistical Calculator with numbers, not words
머신러닝 모델은 단어, 텍스트 형태가 아닌 숫자로 동작하는 계산기 같은 것입니다.
그렇기 때문에 단어를 숫자형태로 바꿔주는 것이 반드시 필요합니다.
You must tokenize the words!
다양한 토크나이저로 단어를 토크나이제이션 할 수 있습니다. 대신 잊지 말아야 할 것은 Text Generation 할 때도 같은 tokenizer를 사용해야 한다는 것.
이렇게 토큰화 된 Input이 그림 속 Embedding Layer로 들어가게 되면, 크게 2개 과정을 거칩니다.
- Embedding Vector Space(Token → Vector)
- Positional Embedding
Self-Attention
모델의 인코더, 디코더에는 Self-Attention을 수행하는 부분이 있습니다.
그렇다면 multi-headed attention은 무엇일까요? Self-attention을 여러 번 동작하는 것이 multi-headed attention 입니다.
각각의 self-attention들이 parallel independently 하게 학습해서 언어의 다른 측면들을 배울 수 있습니다.
맨 처음 각각의 head에 대한 파라미터는 randomly initialized 되고 충분한 학습과 데이터를 거치면, 서로 다른 어텐션 분포를 가질 수 있어 다른 측면도 배울 수 있는거죠!
이런 점 때문에 Attention map, 어텐션 분포를 나타낸 그림에서 어떤 부분은 해석 가능하지만, 해석이 불가능한 부분도 존재합니다.
이렇게 완성된 Attention이 새로운 input에 적용되면 FC를 거쳐 Output을 생성할 수 있습니다.
트랜스포머는 어떻게 문장을 생성할까?
트랜스포머가 동작하는 High-Level Overview는 어느정도 살펴봤습니다. 이제 트랜스포머가 End-to-End 어떻게 동작하는지 살펴봅시다.
Translation Task는 어떻게 동작할까요? 보통 프랑스어 → 영어로 번역할 때 트랜스포머 모델을 사용합니다.
간단하게 다음과 같이 동작합니다.
*Encoder 과정 *
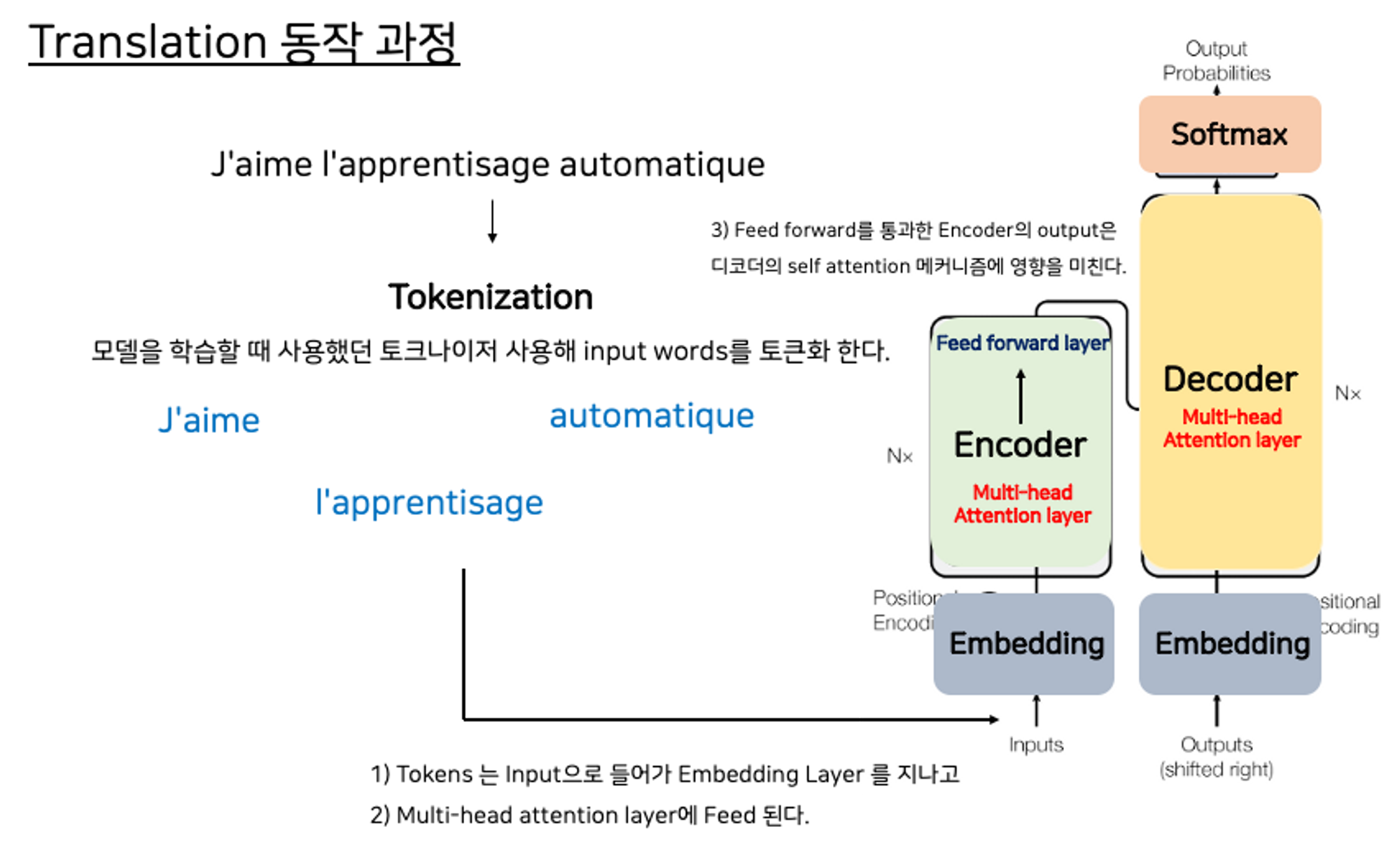
1) 네트워크를 학습할 때 사용했던 토크나이저를 사용해 input words를 토큰화합니다.
2) 이 토큰들은 인코더의 인풋으로 들어가고 ⇒ 임베딩 레이어를 거쳐 ⇒ 멀티헤드 어텐션 레이어에 feed됩니다.
3) 멀티헤드 어텐션 레이어의 아웃풋은 Feed Forward Network에 feed되어 인코더의 아웃풋으로 나옵니다.
💡 강의 속에 중요한 문장이네요! 이렇게 인코더에서 학습한 표현은 나중에 디코더의 어텐션에 큰 영향을 미치게 됩니다.
At this point, the data that leaves the encoder is a deep representation of the structure and meaning of the input sequence.
*Decoder 과정 *
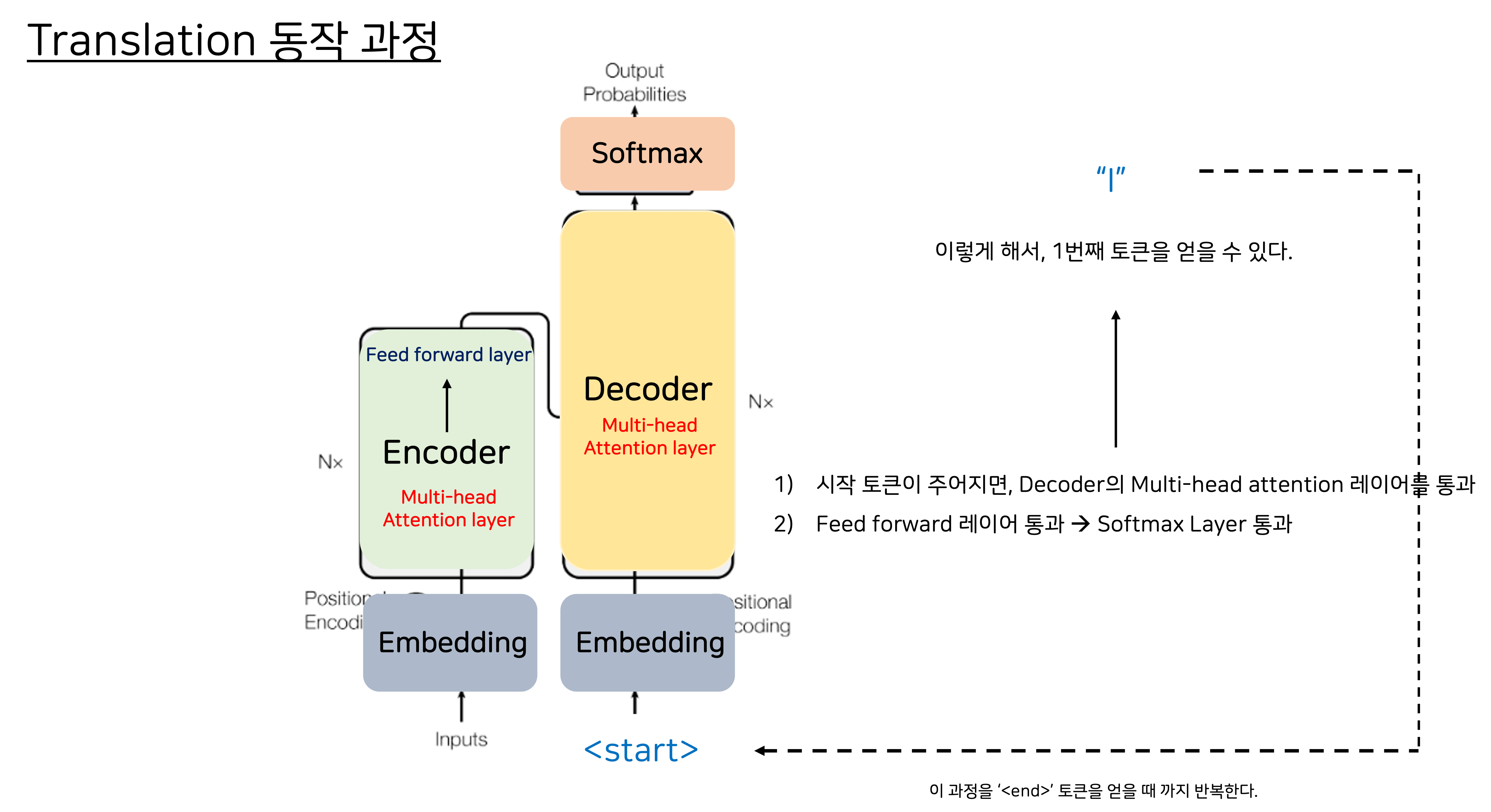
1) 이제 디코더에 토큰이 인풋으로 주어지면, 디코더가 다음 토큰을 예측하게 됩니다.(인코더로부터 제공된 Contextual Understanding에 기반해서)
2) 디코더의 셀프어텐션 레이어의 아웃풋 → Feed Forward Network → Softmax 아웃풋 레이어를 통과합니다.
3) 이렇게해서 1번째 토큰을 얻을 수 있다.
이 과정을 문장의 끝 ‘’ 토큰을 얻을 때 까지 반복합니다.
At this point, the final sequence of tokens can be detokenized into words, and you have your output.
여기서 끝이 아닙니다!
처음에 번역된 완성된 문장을 얻기 위해서는 'detokenized' 과정이 필요합니다. 인코더에 들어가기 전 Tokenize를 거쳤으니까요~
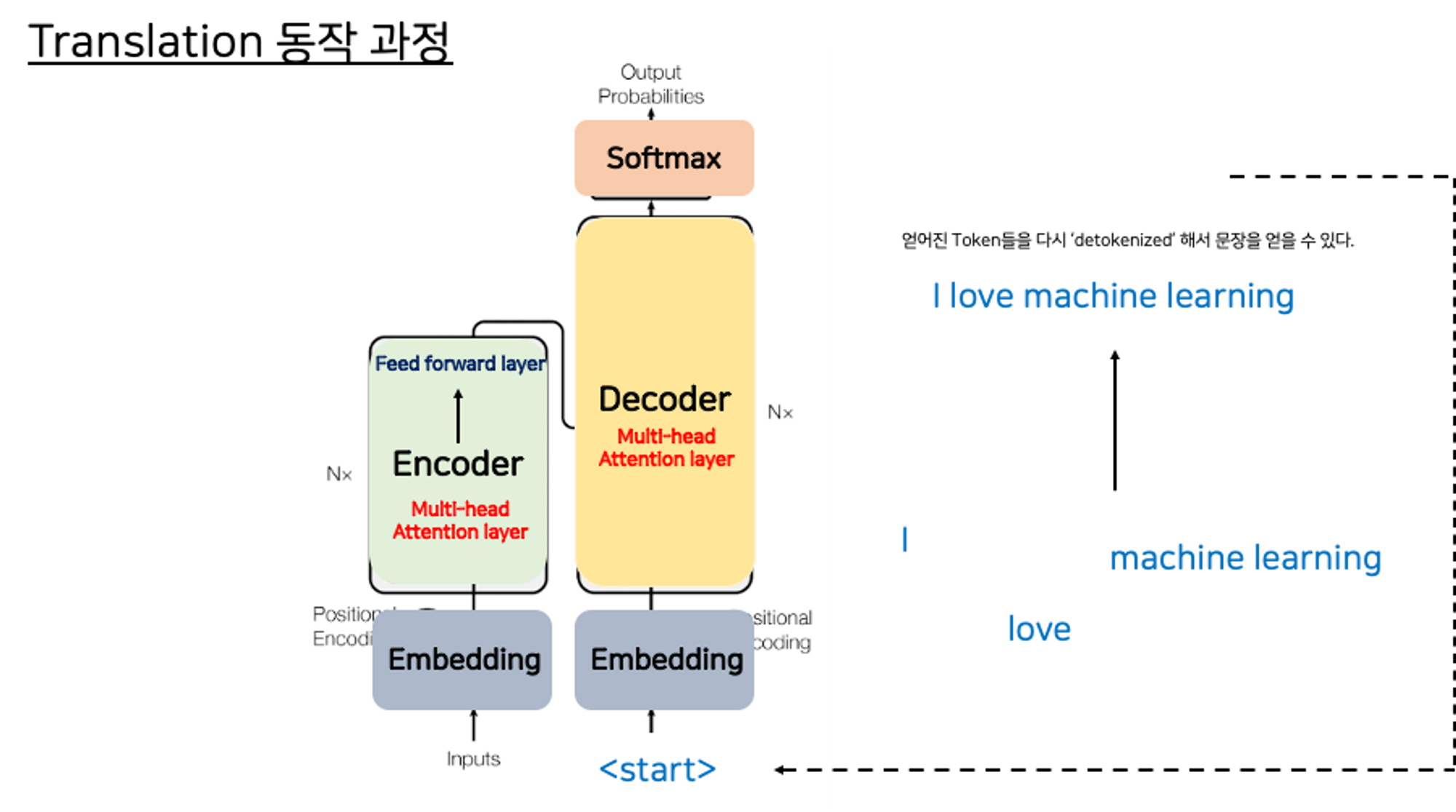
Encoder-Decoder의 동작을 짧게 요약하면?!
이렇게 Transformer가 어떻게 동작하는지 간단하게 살펴볼 수 있었습니다.
트랜스포머 모델의 변형!
인코더-디코더 아키텍쳐가 Task에 따라 다른 모델로 변형될 수 있다는 사실을 아시나요?!
어떤 Task를 다룰지에 따라 인코더-디코더를 Split 할 수 있습니다.
- Encoder Only : 역시 sequence to sequence 모델로 사용할 수 있습니다.(주의: input과 output sequence의 길이를 다르게 하려면 수정이 필요합니다.)
- additional layer가 있다면, classification task도 가능합니다. BERT가 바로 Encoder-only 모델이죠!
- Encoder-Decoder : input sequence, output sequence의 길이가 다른 번역이나 문장 생성 Task에 사용됩니다. BERT나 T5와 달리, BART 같은 모델이 있습니다.
- Decoder Only : most commonly used today. GPT family of models, BLOOM, Jurassic, LLaMA 등이 있습니다.
'Machine & Deep Learning > Generative AI' 카테고리의 다른 글
| [Coursera] Pre-training LLM 구별하기 (0) | 2023.08.16 |
|---|---|
| LLM을 활용한 Prompt Engineering 도전해보기 💪 (0) | 2023.08.10 |
| [Coursera] Generative Configurations : Max tokens, Top-k, Top-p, Temperature (0) | 2023.08.10 |
| [Coursera] Prompt Engineering (0) | 2023.08.09 |
| [Coursera] 앤드류응 교수님의 Generative AI (0) | 2023.08.02 |


