
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 플로이드와샬
- 파인튜닝
- Coursera
- 완전탐색
- Python
- bfs/dfs
- 데이터분석
- Lora
- 코딩테스트실력진단
- 판다스
- English
- 머신러닝
- 알고리즘
- 코딩테스트
- peft
- 프로그래머스
- 그래프이론
- 이분탐색
- 파이썬
- Fine-Tuning
- Generative AI
- 스터디
- Study
- LLM
- DP
- paper review
- speaking
- 최단경로
- 코드트리
- Scaling Laws
- Today
- Total
생각하는 아져씨
[Coursera] LLM을 학습할 때 마주하는 문제점 본문
앤드류 응 교수님의 강의를 듣고 정리 및 공부한 글임을 알려드립니다.
Generative AI with LLMs In Generative AI with Large Language Models (LLMs), created in partnership with AWS, you’ll learn the fundamentals of how generative AI works, and how to deploy it in real-world applications.
Computational challenges
대규모 언어 모델을 학습할 때 가장 흔히 직면하는 문제 중 하나는 메모리 부족입니다.
아마 Nvidia GPU에서 모델을 훈련하거나 로드해 본 적이 있다면 이 오류 메시지가 익숙할지도 모릅니다.
OutofMemoryError : CUDA out of memory.
CUDA(Compute Unified Device Architecture)란, Nvidia GPU 용으로 개발된 라이브러리 및 도구를 모아놓은 것입니다.
흔히 딥러닝 프레임워크로 잘 알려진 Pytorch, Tensorflow 같은 라이브러리도 이 CUDA를 사용하여 행렬 곱셈과 같은 딥러닝의 연산에서 성능을 향상하곤 합니다.
하지만, 요즘 대부분의 LLM은 크기가 커서 파라미터를 저정하고 학습하는데 많은 메모리가 필요하기 때문에 위와 같은 메모리 부족 문제가 발생할 수 있습니다.
10억 개의 파라미터를 저장하는데 필요한 GPU RAM은 얼마나 필요할까요?
LLM을 개인 연구자가 처음부터 학습하기에는 힘들다는 것을 듣긴 했지만, 구체적으로 규모를 계산해 보면 좀 더 직관적으로 파악할 수 있습니다.
일반적으로 단일 파라미터는 실수로 표현이 되는데, 컴퓨터는 이를 실수를 표현하는 방식인 32-bit float(32비트 부동 소수점)으로 표현하고 4-byte의 메모리를 차지하게 됩니다.
따라서 10억개(1B)의 파라미터를 저장하려면 4-byte 메모리의 10억 개 있는 것이므로, 총 4-Gigabyte가 필요하게 됩니다.
수식으로 쓴다면,

즉, 32-bit full precision에서 4기가바이트의 GPU RAM이 필요한 것을 알 수 있습니다.
모델을 학습하고 저장하는데 weight(가중치) 뿐만 아니라 optimizer, gradient, activation memory 등을 고려했을 땐 훨씬 더 많은 메모리가 필요하다는 것을 알 수 있죠!
아래 표와 같이 모델 파라미터가 요구하는 4바이트를 제외한 모든 오버헤드를 고려하면 실제로 20배의 메모리가 더 필요하게 됩니다.
최종적으로 10억개의 파라미터를 가진 모델을 32-bit full precision으로 훈련하려면, 약 80기가 바이트의 GPU RAM이 필요합니다.
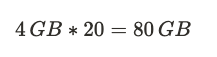
| Byte per parameter | |
| Model Parameters(Weights) | 4 bytes per parameter |
| Adam optimizer(2 states) | +8 bytres per parameter |
| Gradients | +4 bytes per parameter |
| Activations and temp memory (variable size) | + 8 bytes per parameter (high-end estimate) |
| total | = 4 bytes per parameter + 20 extra bytes per parameter |
80GB가 어느정도 크기일까요?
일반적으로 클라우드 머신 러닝 작업에 사용되는 프로세서인 단일 Nvidia A100 GPU의 메모리 용량이 80GB인 것을 생각하면, 일반 소비자가 감당하기에는 큰 용량임을 알 수 있습니다.
👉 개인이 클라우드에서 학습할 수 있는 것은 10억 개의 파라미터를 약 80기가 바이트의 GPU RAM을 사용할 수 있는데 Nvidia A100 GPU 정도 됩니다.
[참고하면 좋은 것]
Efficient Training on a Single GPU from Hugging Face
bitsandbytes
그렇다면 이렇게 많은 메모리를 그대로 사용해야만 할까요? 아닙니다.
학습에 필요한 메모리를 줄일 수 있는 방법으로, Quantizaion(양자화)가 있고, 32-bit full precision의 단어에서 알 수 있듯이 고정밀이 아닌 다르게 표현하는 방법을 활용할 수 있습니다.
Quantization (양자화)
Quantizaion(양자화)는 메모리를 줄이기 위해 사용할 수 있는 기술 중 하나입니다.

주요 아이디어는 모델의 weight을 32-bit float 에서 16-bit float 또는 8-bit int로 정밀도(precision)를 낮춤으로써 저장하는데 필요한 메모리를 줄이는 것입니다.
딥러닝 프레임워크 및 라이브러리에서 사용되는 해당 데이터 유형은 다음과 같습니다.
- 32-bit full precision → FP32
- 16-bit half precision → FP16 또는 BFLOAT16
- 8-bit integer → INT8
각 데이터 유형이 표현할 수 있는 숫자의 범위가 다르다는 것을 눈치챘다면, Quantization 개념을 대충 눈치챌 수 있습니다.
👉 아하~ 그럼 양자화는 원래 FP32로 표현된 숫자의 범위를 기반으로 계산된 Scaling Factor를 사용해서 더 낮은 정밀도 공간으로 투영하는 것이구나!
Quantization statistically projects the original 32-bit floating point numbers into a lower precision space, using scaling factors calculated based on the range of the original 32-bit floating point numbers.
Example : Quantization FP32 → FP16

Floating point(부동소수점)는 컴퓨터가 이해할 수 있는 0과 1로 저장됩니다. 어떤 수를 FP32로 표현하고 싶다면, 양수/음수를 나타내는 sign비트와 숫자의 지수를 나타내는 exponent, 유효숫자를 나타내는 fraction(mantissa or signature)로 나뉘어 표현할 수 있습니다.
그래서 PI(3.14159202575…)를 FP32로 표현한다면 →
0(sign) 10000000 (exponent) 10010010000111111011000(fraction)
으로 표현할 수 있습니다. 단 이 숫자를 다시 십진수로 변환하면 정밀도가 약간 손실됩니다.
다시 양자화로 돌아와서, PI(3.14159202575…)를 소수점 이하 여섯 자리까지 표현하고 싶다고 가정해 보고 양자화를 진행해 보겠습니다.
FP32로 표현된 PI를 더 낮은 precision space를 가진 FP16에 투영한다면, 표현할 수 있는 수의 범위는 다음처럼 바뀌게 됩니다.
0(sign) 10000(exponent) 10010010000(fraction)
FP16에서는 부호를 나타내는데 1-bit, 지수를 나타내는데 5-bit, fraction을 나타내는데 10-bit가 할당됩니다. 따라서 FP16으로 표현할 수 있는 숫자의 범위는 -65,504에서 +65,504로 FP32보다 훨씬 적은 범위를 갖게 됩니다.
따라서 FP32를 FP16으로 투영한다면, 이전보다 정밀도가 떨어지긴 하지만 메모리 사용량을 최적화하기 위한 것이므로 이 정도의 손실은 허용 가능한 수준입니다.
이로써 FP32는 4바이트의 메모리가 필요했지만 FP16은 2바이트의 메모리만 필요하므로 양자화를 통해 메모리를 절반으로 줄일 수 있게 됩니다.
AI 연구 커뮤니티에서는 16비트 양자화를 최적화하는 방법을 모색해 왔습니다. 특히 BFLOAT16이라는 데이터 유형은 최근 FP16의 대안으로 널리 사용되고 있습니다.
BLOAT16
BFLOAT16은 Brain Floating Point Format로, 구글 브레인이 개발했습니다. FLAN-T5 포함 많은 LLM이 BFLOAT16으로 사전훈련되었습니다.
- Training stability에 큰 도움이 되는 방식입니다.
- Nvidia A100 같은 최신 GPU에서 지원되고,
- half precision FP16과 full precision FP32의 하이브리드 방식입니다.
- 32-bit float의 full dynamic range 중 잊고 16-bit 만을 사용해서 truncated 32-bit float로 불린다고도 합니다.
그럼 더 구체적으로 살펴볼까요?

FP32을 BFLOAT16으로 투영시킬 때, FP32의 full dynamic range 중 16-bit만 가져오게 됩니다.
따라서 sign을 나타내는 1-bit, 지수를 나타내는 8-bit, fraction을 나타내는 7-bit로 구성됩니다. 이로써 메모리를 2바이트로 줄일 수 있게 됩니다.
👉 BF16은 메모리를 줄이고 계산 속도를 향상해 모델의 성능을 높여주는 장점이 있습니다.
양자화 요약
지금까지 내용을 바탕으로 Quantization을 요약해 볼까요?
- 모델의 weight의 precision(정밀도)를 낮춤으로써 모델을 저장하고 학습하는데 필요한 메모리를 줄이는 것!
- scaling factor을 사용해서 32-bit floating point → lower precision space에 투영하는 것!
- BF16은 FP32의 dynamic range을 유지하고 메모리 사용량을 절반으로 줄임으로써 → popular choice of precision in deep learning!
| Bits | Exponent | Fraction | Memory needed to store one value | |
| FP32 | 32 | 8 | 23 | 4 bytes |
| FP16 | 16 | 5 | 10 | 2 bytes |
| BFLOAT16 | 16 | 8 | 7 | 2 bytes |
| INT8 | 8 | -/- | 7 | 1 byte |
하지만, LLM을 GPU 메모리에 맞추는데 현실적 문제
양자화라는 기법을 통해서 메모리를 절반으로 줄이는 효과를 볼 수 있었습니다.
처음에 예시를 들었던 10억 개의 파라미터를 가지는 모델이 있을 때, 양자화를 활용하면,
32-bit full precision → 16-bit or 8-bit precision으로 투영, 4GB → 2GB → 1GB까지 메모리를 줄일 수 있게 됩니다.
하지만, 현재 많은 모델은 1B에서 그치지 않고 50B, 100B개의 파라미터를 초과한다는 현실적인 문제가 있죠🥲
이런 문제 때문에
- single GPU 학습이 불가능해지고,
- distributed computing technique과 multi-gpu를 사용해야 합니다.
- 이렇게 되면 비용이 많이 들게 됩니다.
이것이 바로 개인 연구자가 pre-train 모델을 스크래치부터 학습할 수 없는 이유입니다.
그럼 새로운 domain, task에 대해 사전학습을 처음부터 할 수 없다면, 개인 연구자는 어떻게 해야 할까요?
바로 이를 해결할 수 있는 개념이 Fine-tuning입니다.
우리는 Fine-tuning을 활용해 추가학습을 할 수 있게 됩니다.
참고
'Machine & Deep Learning > Generative AI' 카테고리의 다른 글
| [Coursera] 모델 성능 개선을 위해 선택할 수 있는 요소 : compute budget, model size, dataset size (1) | 2023.09.03 |
|---|---|
| [Coursera] LLM에 필요한 효율적인 Multi-GPU 활용 전략 (1) | 2023.09.02 |
| [Coursera] Pre-training LLM 구별하기 (0) | 2023.08.16 |
| LLM을 활용한 Prompt Engineering 도전해보기 💪 (0) | 2023.08.10 |
| [Coursera] Generative Configurations : Max tokens, Top-k, Top-p, Temperature (0) | 2023.08.10 |


