
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코딩테스트
- Python
- Generative AI
- bfs/dfs
- 머신러닝
- speaking
- Coursera
- 그래프이론
- 프로그래머스
- 이분탐색
- Scaling Laws
- English
- 데이터분석
- paper review
- 파인튜닝
- 알고리즘
- 코딩테스트실력진단
- DP
- 스터디
- peft
- LLM
- 판다스
- 파이썬
- 완전탐색
- 최단경로
- Study
- 플로이드와샬
- 코드트리
- Fine-Tuning
- Lora
- Today
- Total
생각하는 아져씨
[Coursera] 모델 성능 개선을 위해 선택할 수 있는 요소 : compute budget, model size, dataset size 본문
[Coursera] 모델 성능 개선을 위해 선택할 수 있는 요소 : compute budget, model size, dataset size
azeomi 2023. 9. 3. 23:15앤드류 응 교수님의 강의를 듣고 정리 및 공부한 글임을 알려드립니다.
Generative AI with LLMs
In Generative AI with Large Language Models (LLMs), created in partnership with AWS, you’ll learn the fundamentals of how generative AI works, and how to deploy it in real-world applications.
이제 LLM은 사전학습 시 단일 GPU가 아니라 Multi-GPU를 사용해야 할 만큼 크기가 매우 크고 많은 예산이 필요하게 되었습니다.
무작정 컴퓨팅 예산만 투자한다고 해서 최적의 모델을 만들 수 있을까요? 더 적은 컴퓨팅 예산으로 비슷한 수준의 성능을 가지는 모델을 완성할 수 있다면 더 좋지 않을까요? 🧐
오늘은 바로 이 주제에 대해 공부를 해보려고 합니다.
여러가지 컴퓨팅 예산과 모델의 성능 사이에서 어떻게 최적의 모델을 완성할 수 있을지를 알아보겠습니다.
사전학습을 위한 Scaling choices
사전학습을 하는 목표는 바로 ‘Maximize model performance’입니다. 즉 모델의 Loss를 줄임으로써 높은 성능을 가지는 모델을 얻는 것이 목표입니다.
사실 모델의 성능을 향상시킬 수 있는 옵션에는 2가지가 있습니다.
- 데이터셋 사이즈 증가 ( = LLM의 Token 수 증가)
- 모델의 사이즈 증가 ( = LLM의 parameter 수 증가)
이 2가지 옵션을 활용해서 사전학습 시 모델의 성능을 높일 수 있게 됩니다.
그런데 아쉽게도, 무작정 이 2가지만 가지고 좋은 성능의 사전학습을 진행할 수 없습니다. 왜냐면 GPU의 개수, 학습 소요 시간과 같은 Computing budget(컴퓨팅 예산)도 고려해야 하기 때문입니다.

그럼 모델의 Compute budget을 어떻게 고려해야 할까요?
이를 알기 위해서 컴퓨팅 예산을 측정할 수 있는 단위, 즉 모델을 학습하는데 필요한 Resources를 정량화하는 컴퓨팅 단위를 먼저 살펴보겠습니다.
LLM을 학습하는데 필요한 Compute budget
1 PetaFlop 이라는 단위를 들어본 적이 있나요?
1 PetaFlop(페타플롭) / s
10의 15제곱을 나타내는 접두어 페타(Peta)와 컴퓨터 성능 단위인 플롭스(Flops)를 합성한 용어로 1초당 1,000조 번의 부동소수점 연산처리를 수행한다. 1페타플롭스 프로세서를 장착한 컴퓨터는 펜티엄 133 Mhz 프로세서보다 1억 배 빠른 연산처리속도를 갖는다. - 정보통신용어사전
하루종일(24시간) 동안 초당 1000조개의 부동 소수점 연산을 수행하는데 소요되는 전력을 기준으로 삼는 단위를 말합니다.
1 PetaFlop = 1,000,000,000,000,000 floating point operations per second
단위 이름에서 알 수 있듯이, **FLOPs(FLoating point OPerations)**는 부동소수점 연산을 의미합니다.
이 단위로 어떻게 모델을 학습하는 컴퓨팅 예산을 측정할 수 있는지 감을 잡기가 처음에는 쉽지 않았습니다. 그냥 연산을 몇 번 하느냐에 따라 필요한 GPU 연산의 양이 다른가보다~ 하고 이해했었습니다.
예시로 보면 좀 더 이해가 수월했습니다.
만약 Transformer(트랜스포머)을 학습한다고 했을 때, 1 PetaFlop/s 는 하루종일 최대 효율로 동작하는 8개의 NVIDIA V100 GPU에 해당한다고 합니다.
이보다 더 많은 연산을 한번에 처리할 수 있는 강력한 프로세서가 있다면, 당연히 1 PetaFlop/s는 8개보다 더 적은 칩을 사용할 수 있게 됩니다.
아래의 차트는 GPT-3 논문인 ‘Language Models are Few-Shot Learners’에서 가져온 차트입니다.
사전학습 모델의 다양한 변형 모델들을 학습하는데 필요한 PetaFlop/s 을 비교한 내용입니다. 이 차트만 봐도 큰 모델을 학습시킬수록 엄청난 양의 컴퓨터가 필요함을 알 수 있죠!
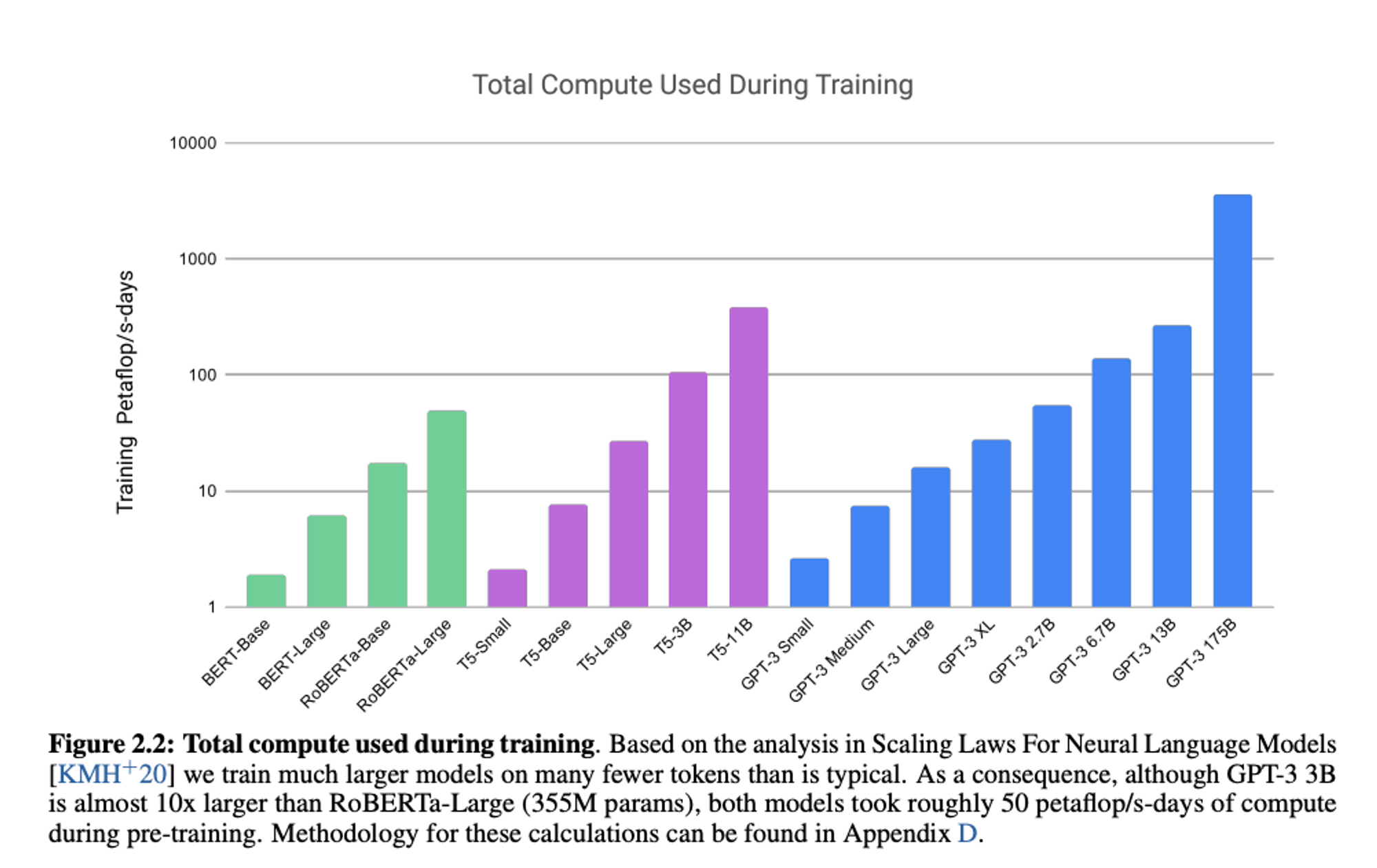
Trade off : dataset size & model size & compute budget
앞에서 살펴보았듯이 큰 모델은 많은 컴퓨팅 예산이 필요하고, 일반적으로 좋은 성능을 내기위해서 많은 데이터를 필요로 합니다.
이러한 관계 즉, 학습 데이터셋 사이즈, 모델 사이즈, 컴퓨터 예산 사이의 Trade-off 관계는 이미 여러 연구를 통해 잘 알려져 있습니다.
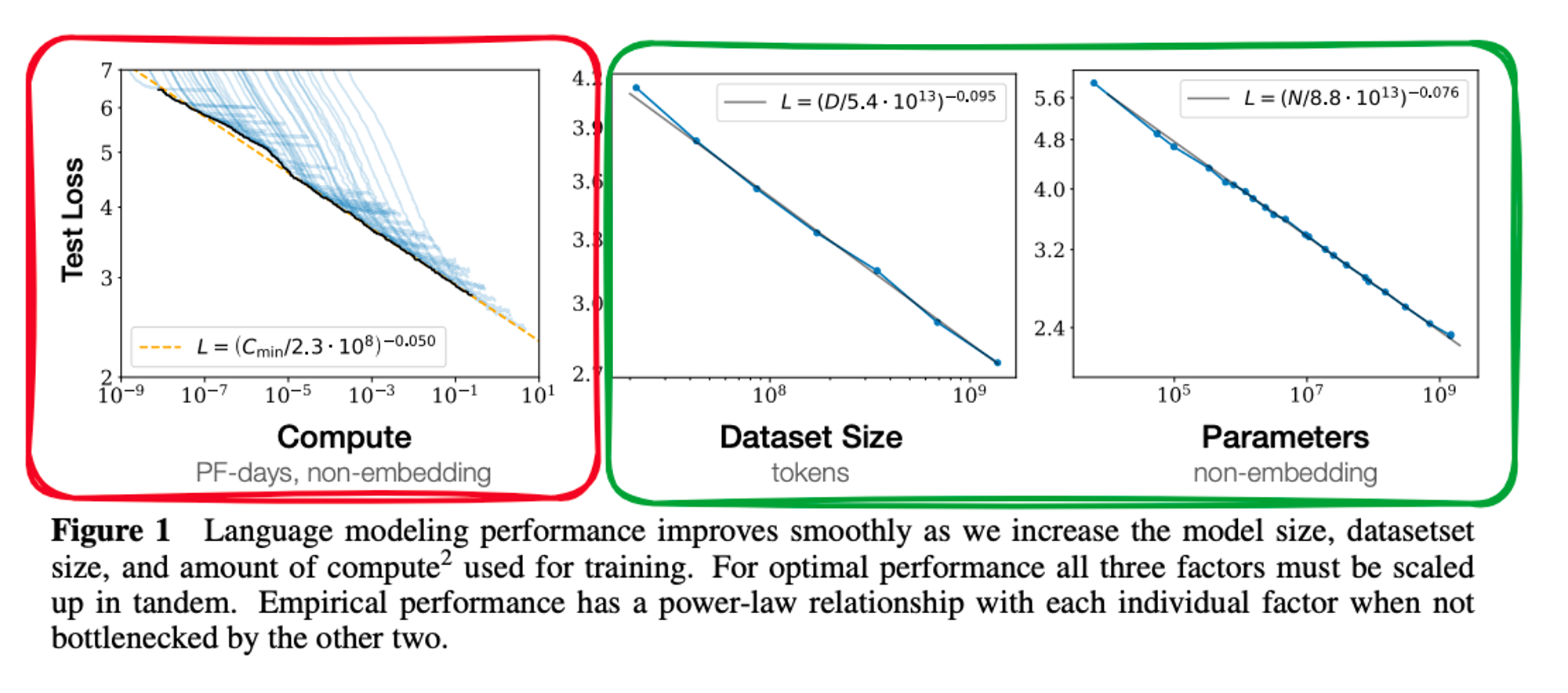
1. Compute budget VS Model performance
Computing Budget과 모델 성능 사이의 관계를 살펴볼까요?
논문(빨간 박스)에 따르면, Computing Budget을 늘리면 → 모델의 Performance(=Test Loss)을 개선할 수 있음을 알 수 있습니다.
하지만, 보통 컴퓨팅 리소스와 제한된 학습시간 또는 프로젝트 예산의 한계 등과 같은 이유로 Computing Budget을 원하는 만큼 늘릴 수 없는 상황을 맞닥뜨리게 됩니다. 🥲
그렇기 때문에 만약 Compute budget이 정해진다면 다른 방법을 활용해 모델의 성능을 높여야 합니다.
그 대안으로 선택할 수 있는 방법이 바로 학습 데이터셋 사이즈와 모델 사이즈를 조절하는 것입니다.
scaling choices → training dataset size & model size
2. Dataset size & Model size VS Model performance
초록 박스를 살펴봤을 때도,
데이터셋 사이즈를 늘리면 → Test Loss가 줄어들고
모델의 사이즈를 늘리면(=파라미터 개수를 증가) → Test Loss 역시 줄어드는 것을 확인할 수 있습니다.
자세한 설명은 논문을 읽어보는 것을 추천드립니다.
자, 그렇다면 지금까지 모델의 성능을 개선시킬 수 있는 3가지 요소를 살펴봤습니다.
Compute budget, Model size, Dataset size 간의 가장 이상적인 밸런스는 무엇일지 궁금해지는데요🧐
이와 관련된 논문이 계속 연구되고 있고, 그 중 하나가 바로 잘 알려진 Chinchilla paper 입니다.
Chinchilla paper(친칠라)
논문의 Full name은 Training Compute-Optimal Large Language Models입니다.

모델 이름이 너무나도 귀여운 친칠라입니다🥰
사실 이 논문의 목적은 주어진 Compute Budget에서 최적의 parameter 수와 데이터셋 사이즈를 찾는 것입니다.
이 논문을 통해 최근에는 non-optimal 방식으로 학습된 대형 모델보다 나은 결과는 아니더라도, 비슷한 결과를 얻을 수 있는 소형 모델을 개발하기 시작했다고 합니다. (ex. bloomberg gpt)
딥마인드의 친칠라(Chinchilla) 모델 논문에서는 이전의 언어 모델은 학습 데이터를 충분히 투입하지 않아서 덜 학습되었다고 주장하고 있고,
학습 데이터를 많이 투입한 70B 크기의 친칠라 모델이 덜 투입한 280B 크기의 고퍼(Gopher) 모델을 능가하는 것을 보여주고 있습니다.
자세한 내용은 논문을 확인해 주시면 좋을 것 같습니다.🥰
친칠라 논문 리뷰도 해봤습니다.
여기서 자세한 내용을 확인해주세요!
'Machine & Deep Learning > Generative AI' 카테고리의 다른 글
| Fine-tuning - Instruction Fine-tuning에 대해서 (0) | 2023.09.12 |
|---|---|
| [Coursera] 도메인을 고려한 사전학습과 BloombergGPT (0) | 2023.09.04 |
| [Coursera] LLM에 필요한 효율적인 Multi-GPU 활용 전략 (1) | 2023.09.02 |
| [Coursera] LLM을 학습할 때 마주하는 문제점 (0) | 2023.09.02 |
| [Coursera] Pre-training LLM 구별하기 (0) | 2023.08.16 |



