
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 머신러닝
- 코딩테스트
- 코드트리
- Scaling Laws
- 스터디
- Generative AI
- 플로이드와샬
- 알고리즘
- 파이썬
- Lora
- 이분탐색
- bfs/dfs
- 판다스
- 최단경로
- 프로그래머스
- English
- 코딩테스트실력진단
- LLM
- paper review
- peft
- 완전탐색
- Study
- Python
- 그래프이론
- speaking
- Fine-Tuning
- 데이터분석
- 파인튜닝
- DP
- Coursera
- Today
- Total
생각하는 아져씨
Fine-tuning - Instruction Fine-tuning에 대해서 본문
Fine-tuning - Instruction Fine-tuning에 대해서
azeomi 2023. 9. 12. 12:18앤드류 응 교수님의 강의를 듣고 정리 및 공부한 글임을 알려드립니다.
Generative AI with LLMs In Generative AI with Large Language Models (LLMs), created in partnership with AWS, you’ll learn the fundamentals of how generative AI works, and how to deploy it in real-world applications.
이번 주는 LLM의 Fine-tuning에 대해서 살펴보려고 합니다.
그중에서도 Instruction fine-tuning과 parameter fine-tuning 이렇게 2가지에 대해 공부해 보겠습니다.
Instruction Fine-tuning
LLM은 많은 Text 데이터 위에서 학습을 했기 때문에 이미 많은 정보를 담고 있습니다. 하지만 가끔 우리가 던지는 질문, 즉 Prompts(프롬프트)에 어떻게 응답을 해야 하는지 모를 때가 있습니다.
왜 이런 일이 발생하는 걸까요~?
왜냐하면, LLM은 원래 Next token(다음에 등장할 단어 or 빈칸에 들어갈 단어)을 예측하는 방법으로 학습을 진행했기 때문입니다. 사실 우리가 던지는 지시문에 따라 LLM이 대답하는 방식은 “Next Token”을 예측하는 것과는 다르기 때문에 이를 잘할 수 있도록 하는 breakthrough가 필요하게 되는데요!
Instruction Fine-tuning 이 바로 그 해결책입니다.
이 Fine-tuning은 나만의 Task를 잘할 수 있도록 하는 장점도 있지만 그에 따른 단점도 존재합니다. 바로 Catastrophic Forgetting입니다.
Fine-tuning을 하면서 해당 도메인도 잘할 수 있도록 하는 추가 데이터를 사용하고 모델을 학습하게 되는데, 이 과정에서 전에 가지고 있던 Stuff 또는 데이터들의 big chunk들을 잊어버리는 현상이 발생합니다. 이것이 바로 Catastrophic Forgetting이고, 따라서 LLM을 파인튜닝할 땐 이런 문제도 고려해야 합니다.
Parameter Fine-tuning - PEFT
특정 Task와 Domain에 대해서도 좋은 성능을 얻을 수 있도록 Fine-tuning을 할 수 있었습니다. 하지만 모델의 크기가 크고 학습 시간이 부족하다면 파라미터 전체를 Fine-tuning 하는 것보다 효율적으로 하는 게 훨씬 더 이득입니다.
Full Fine-tuning을 통해 얻을 수 있는 성능을 효율적인 Fine-tuning으로 유사한 성능을 얻을 수 있도록 하는 방법도 존재합니다. 그것이 바로 PEFT이고, 그중 하나가 유명한 LoRA입니다.
이번 포스팅에서는 첫 번째인 Instruction fine-tuning을 자세히 공부해 보겠습니다.
Instruction Fine-tuning
Generative AI Project Cycle의 모델학습 파트에서 볼 수 있는 Fine-tuning은 특정한 use case에서도 모델의 성능을 높일 수 있는 방법 중 하나입니다.

Fine-tuning은 무엇이고 왜 등장하게 되었을까요?! 🧐
Limitations of In-Context Learning
저번에 “Prompts Engineering”을 공부했을 때, 어떤 모델은 Example(예제) 없이도 질문에 답을 잘하는 반면에, 작은 모델은 Zero-shot Inference에는 잘하지 못하는 것을 확인했었습니다.
대신에 이 경우, One-shot & Few-shot을 통해서 더 좋은 답변을 생성할 수 있었죠! 👉 Better Completion
하지만 모델의 성능을 높이는 이런 전략에는 몇 가지 단점이 존재합니다.
첫 번째, 작은 모델에서는 이 전략이 항상 통하는 것은 아닙니다. (보통 권장하는 Prompts로 5~6개를 말하는데, 이 경우에도 부족할 수 있죠)
두 번째, Example들이 Prompts가 들어갈 공간을 차지하게 되면서 Context Window에 다른 유용한 정보를 포함할 수 있는 공간이 줄어들게 됩니다.
바로 Fine-tuning은 이런 문제를 해결해 줍니다.
방대한 양의 unstructured data를 Self-Supervised Learning으로 학습시키는 LLM과 달리, Fine-tuning은 Lable이 지정된 Dataset을 사용해서 LLM의 Weights을 Supervised Learning으로 학습합니다.
Fine-tuning an LLM with Instruction Prompts
그럼, Supervised Learning에서 사용되는 학습 데이터, 즉 레이블이 지정된 데이터는 어떤 것을 말하는 걸까요?
바로 Prompts와 그에 따른 답변(=Completion)이 쌍으로 존재하는 “Prompts Completion Pairs”입니다. 이를 통해 특정 Task에 대해서도 올바른 Completion을 생성하는 능력을 향상해 모델을 확장할 수 있는 것입니다. 😁
그중 한 가지 전략이 바로 Instruction Fine-tuning입니다.

Instruction Fine-tuning
Instruction Fine-tuning은 모델에게 특정 Instruction(지시문)에 어떻게 대답해야 하는지 보여주는 예제들을 활용해서 모델을 학습시키는 방법입니다.
예시를 살펴볼까요?!

그림처럼, 문장의 긍정/부정을 분류하는 Instruction(지시문)이 있다면, 우리가 원하는 답변이 나오도록 그에 맞는 Completion Pair를 학습시켜 주는 방식입니다.
그래서 만약 요약을 잘하고 싶다면 요약 지시문을, 번역을 잘하고 싶다면 번역 지시문을 포함하는 데이터 쌍을 활용하면 됩니다.

이런 식으로 주어진 Instruction에 따라 응답하도록 하는 방식인 Instruction Fine-tuning은 사실 새로운 데이터셋을 학습하면서 모든 Weight가 업데이트됩니다.
그래서 Full Fine-tuning으로 말할 수 있습니다.
그렇기 때문에 Instruction Fine-tuning도 Pre-training처럼 model weights, gradients, optimizer 등을 저장하고 처리하는데 많은 메모리와 Compute Budget이 필요하다는 것을 알고 있어야 합니다.
How to go about Instruction Fine-tuning
자, 이제 Instruction Fine-tuning은 어떤 과정으로 진행되는지 간략하게 살펴보겠습니다.
1) 학습 데이터셋 준비하기
Instruction Fine-tuning을 위한 학습 데이터셋을 준비해야 합니다. 기존 언어모델에 쓰인 많은 학습 데이터가 있긴 하지만, 대부분 just text 형식이지, 명령어 포맷을 가지고 있진 않습니다.
다행히도 개발자들이 기존 데이터셋을 Instruction Prompt dataset으로 사용할 수 있도록 템플릿 라이브러리를 구축해 준 덕분에 fine tuning을 진행할 수 있습니다.
여기에 보면 다양한 데이터셋과 그에 대한 템플릿이 잘 정리되어 있습니다.
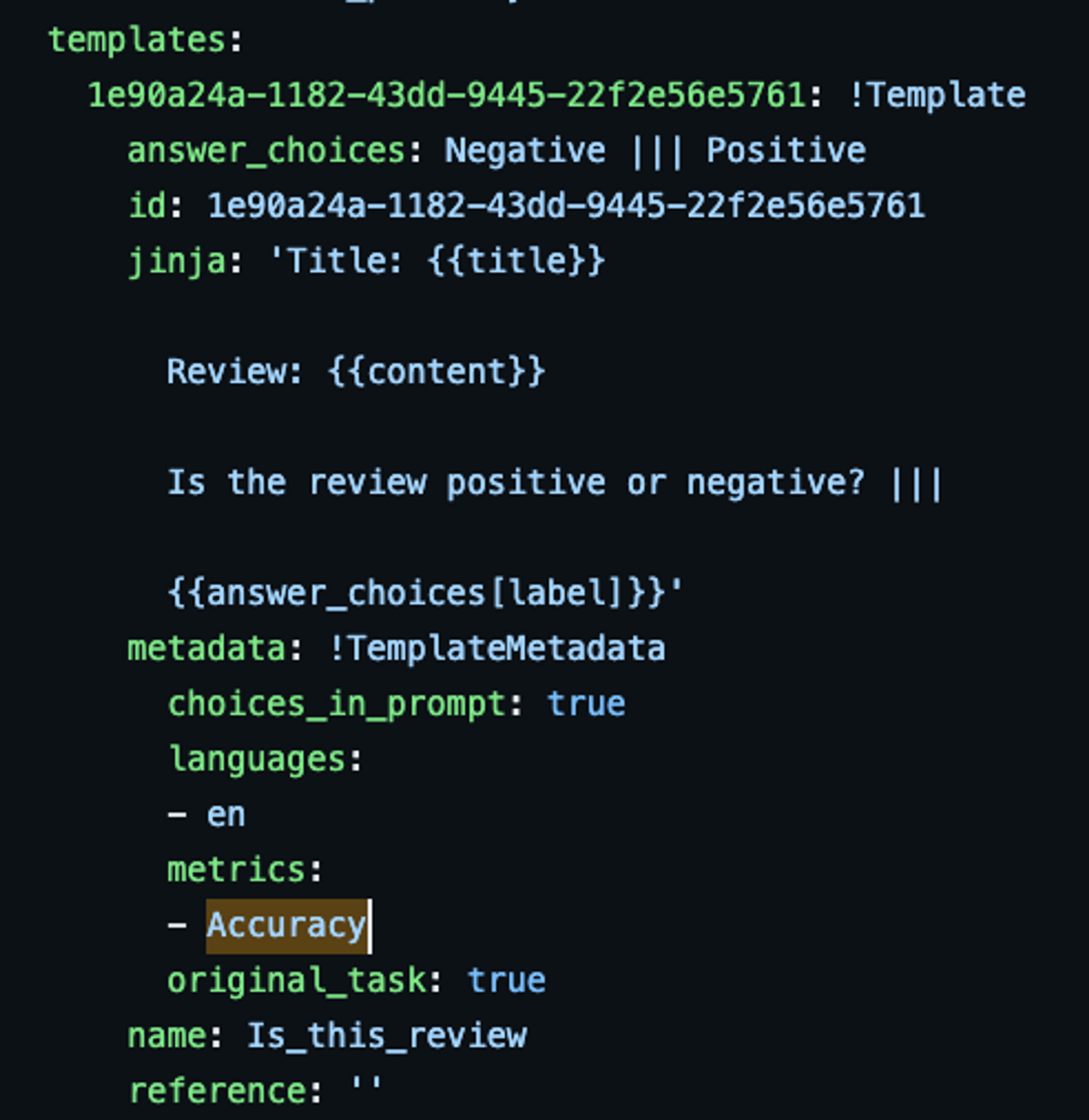
- Review: {{content}} → 오리지널 Text가 들어갑니다.
- Is the review positive or negative? → Instructions, 즉 지시문입니다. 다양한 지시문이 존재합니다.
이 방법을 통해서 다양한 명령어와 데이터셋의 example이 포함된 prompts를 얻을 수 있게 됩니다.
2) Supervised Learning (지도학습)
기존 머신러닝, 딥러닝의 학습 방식처럼 진행할 수 있습니다.

- 먼저, 데이터셋을 Train & Valid & Test로 분리하여 학습을 진행합니다.
- LLM에 prompt를 던져서 얻을 LLM의 Completion(답변)과 학습 데이터에 지정된 답변을 비교합니다.
- Completion의 distribution과 학습 데이터셋의 레이블 distribution을 비교하여 Cross-Entropy 함수를 사용해서 두 분포 사이의 Loss를 계산할 수 있습니다.
- Backpropagation을 통해 모델을 업데이트합니다.
3) Evaluate (평가)
일반적인 supervised learning처럼, holdout validation set을 사용해서 validation accuracy를 측정합니다.
fine-tuning을 완료한 후에는 Test dataset을 사용해서 최종 성능 평가를 진행할 수 있고 이를 통해 Test Accuracy를 얻으면 됩니다.
이렇게 Instruction을 사용해서 Fine-tuning 하는 방법은 LLM을 fine-tuning 하는데 흔하게 사용되는 방법입니다.
하지만 앞서 말씀드렸듯이 Instruction Fine-tuning은 Full Fine-tuning에 속한다는 점, Catastrophic forgetting의 문제점이 있는 점을 고려했을 때 해결해야 할 부분이 아직 남아있습니다.
이 부분에 대해서는 다음 주에 더 공부해 보도록 하겠습니다.
'Machine & Deep Learning > Generative AI' 카테고리의 다른 글
| Fine tuning 후 Model Evaluation(ROUGE, BLEU, Benchmarks) (0) | 2023.09.14 |
|---|---|
| Instruction Fine-tuning과 Catastrophic Forgetting (0) | 2023.09.13 |
| [Coursera] 도메인을 고려한 사전학습과 BloombergGPT (0) | 2023.09.04 |
| [Coursera] 모델 성능 개선을 위해 선택할 수 있는 요소 : compute budget, model size, dataset size (1) | 2023.09.03 |
| [Coursera] LLM에 필요한 효율적인 Multi-GPU 활용 전략 (1) | 2023.09.02 |



