
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- bfs/dfs
- Scaling Laws
- peft
- speaking
- Lora
- 코딩테스트실력진단
- LLM
- 파이썬
- 최단경로
- Fine-Tuning
- paper review
- 코드트리
- 완전탐색
- 스터디
- English
- 플로이드와샬
- 데이터분석
- DP
- 프로그래머스
- 그래프이론
- Study
- Python
- 코딩테스트
- 알고리즘
- 파인튜닝
- 이분탐색
- Coursera
- Generative AI
- 머신러닝
- 판다스
- Today
- Total
생각하는 아져씨
[Coursera] 도메인을 고려한 사전학습과 BloombergGPT 본문
[Coursera] 도메인을 고려한 사전학습과 BloombergGPT
azeomi 2023. 9. 4. 10:14앤드류 응 교수님의 강의를 듣고 정리 및 공부한 글임을 알려드립니다.
Generative AI with LLMs
In Generative AI with Large Language Models (LLMs), created in partnership with AWS, you’ll learn the fundamentals of how generative AI works, and how to deploy it in real-world applications.
애플리케이션을 개발할 때 일반적으로 LLM을 사용한다면 많은 이점을 얻을 수 있습니다. LLM을 통해 시간도 절약할 수 있을뿐더러 빠르게 프로토타입도 작성해 볼 수 있으니까요.👍
하지만, 응용하려는 분야가 일반적으로 사용하지 않는 언어구조를 가지고 있다면 이야기가 살짝 달라집니다.
예를 들어 법률, 의학 또는 과학 분야에서 쓰이는 언어의 특징을 고려해보면, 일반적인 LLM의 언어구조와 살짝 다르기 때문에 existing LLM을 그대로 쓸 수 없게 됩니다.
때로는 처음부터 이런 언어를 다룰 수 있는 자체 모델을 사전학습 해야할 수도 있습니다.
좀 더 자세한 예시를 살펴보기 위해 다음 상황을 가정해보겠습니다.
당신은 변호사, 법률 보조원에게 도움이 될 수 있는 법률 요약 애플리케이션을 만들어야 합니다.
단순하게 생각한다면, LLM을 활용해 요약 Task를 진행하면 되겠구나~라고 떠올릴 수 있지만, 법률 문서에 쓰이는 단어의 특성을 생각한다면 쉽게 적용하기는 힘들 것입니다.
법률 문서에는 일반적인 LLM의 학습 데이터에 존재할 가능성이 적은 단어들이 존재하기 때문입니다.
💡 법률 문서 예시
The prosecutor had difficulty proving mens rea, as the defendant seemed unware that his actions were illegal.
The judge dismissed the case, citing the principle of res judicata as the issue had already been decided in a previous trial.
Despite thesigned agreement, the contract was invalid as there was no consideration exchanged between the parties.
- mens rea의 뜻을 찾아보니 범죄의 고의성을 뜻하는 것 같았습니다.
- → 형사책임이 성립되기 위해서는 피의자의 범죄에 대한 주관적 요소(mens rea)와 더불어 객관적 행위요소(actus reus)가 동시에 존재할 것이 요구되는 바, 앞에서 살펴본 actus reus가 범죄의 외부적 행위 요소를 의미하는 것이라면, mens rea는 내부적 주관적 요소인 범의(guilty mind)를 의미하는 것이다. 다양한 범죄들은 각기 다른 mens rea를 요구하는데, 예컨대 살인죄에서 요구하는 mens rea는 죽이려는 의도나 신체에 중상해를 입히려는 의도라면, 구타(battery) 죄의 mens rea는 무력을 행사하려는 의도(intention)나 무력행사에 대한 무모함(recklessness)이다. - 법무정책연구원
- res judicata는 잘 나오지 않아서 논문을 찾아보니, “기판력(Res Judicata)이란 전소법원에서 최종판결이 내려진 후에는 후소법원에 제기된 동일한 청구에 대하여 다시 판결을 받을 수 없는 판결의 효력을 의미한다.”라고 합니다.
- 3번째 문장의 consideration은 일반 대화에서는 ‘고려’라고 해석될 수 있지만 법률 문서에서는 ‘대가’라고 해석이 되고 있습니다.
이 처럼 일반적인 LLM이 학습했을 것 같지 않은 단어들이 등장하는 예시를 살펴볼 수 있었습니다.
비슷하게 의학 분야 또한 이런 특징을 보입니다. 흔하지 않은 단어, 일상생활에 잘 쓸 수 없는 의학 용어등이 많이 포함되어 있습니다.
💡 의학 용어 예시
After a strenuous workout, the patient experienced severe myalgia that lasted for several days.
After the biopsy, the doctor confirmed that the tumor was malignant and recommended immediate treatment.
Sig : 1 tab po qid pc & hs
- myalgia는 근육통을 의미합니다.
- biopsy는 조직검사를 의미하네요!
- 마지막 3번째 문장은 도저히 해석할 수 없는 문장인데요, 의사들이 처방전을 작성할 때 쓰는 속기라고 합니다. 😂 이런 건 당연히 일반 LLM으로 다룰 순 없겠죠!
우리가 알고 있는 일반적인 LLM은 Booktext나 Web으로부터 얻은 Text를 학습한 모델입니다. 그렇기 때문에 이런 특별한 단어를 포함하는 도메인에서는 성능이 제대로 나올 수 없겠죠!
따라서, Highly specialized 도메인(법률, 의학, 금융 등)에서는 모델을 스크래치부터 사전학습 하는 것이 훨씬 더 나은 성능을 얻을 수 있습니다.
이렇게 특정 도메인에 대해 사전학습한 모델의 예시로는 Finance 데이터에 대해 사전학습한 BloombergGPT가 존재합니다.
Bloomberg GPT
Bloombert GPT는 finance data에 대해 사전학습한 LLM입니다. Finance data와 purpose tax 데이터를 결합하여 금융 벤치마크에서 BestinClass를 달성하는 모델입니다.
이뿐만 아니라 일반적인 LLM 벤치마크에서도 경쟁력 있는 성능을 보여주었다고 하네요!
51%의 금융 데이터와 49%의 public data를 선택했고 논문에 따르면 Bloomberg GPT는 Chilchilla paper의 Scaling laws를 적용해 Trade-off를 맞춰나간 것으로 보입니다.
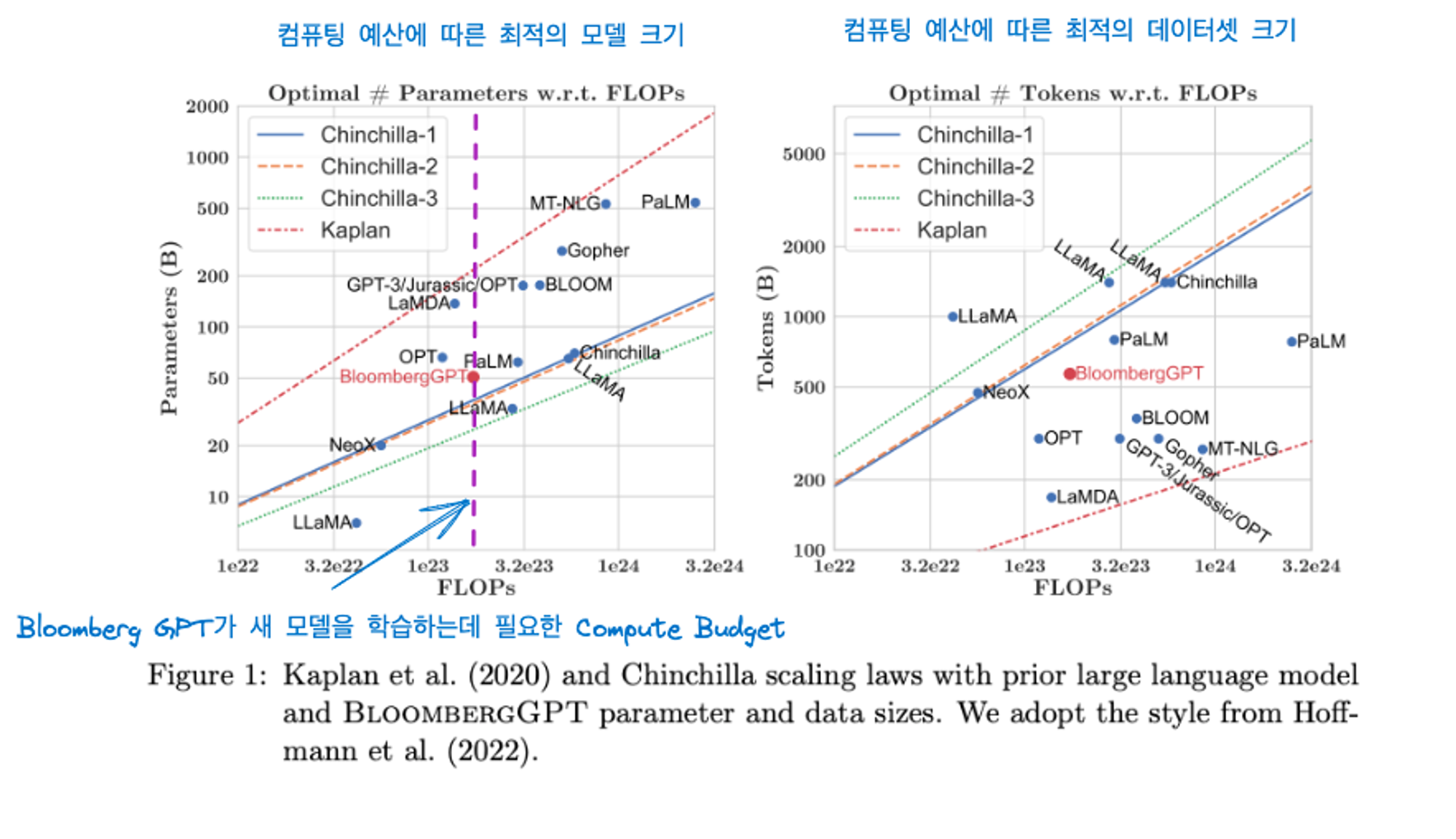
Bloomberg GPT 논문에 나와있는 그림입니다.
매개변수 그래프에서 Bloomberg GPT는 Chinchilla가 제안한 수치와 비교했을 때 최적에 가까운 것을 확인할 수 있습니다.
하지만 오른쪽 그림의 데이터셋 크기 그림에서는 Bloomberg GPT가 chinchilla가 제안한 최적에 못 미치는 것을 확인할 수 있습니다. 실제로 Bloomberg GPT가 569,000,000,000개의 토큰 수로 권장 사항보다 살짝 낮다고 합니다. 이는 금융 도메인 특성상 데이터 가용성이 제한적이기 때문이라고 합니다.
'Machine & Deep Learning > Generative AI' 카테고리의 다른 글
| Instruction Fine-tuning과 Catastrophic Forgetting (0) | 2023.09.13 |
|---|---|
| Fine-tuning - Instruction Fine-tuning에 대해서 (0) | 2023.09.12 |
| [Coursera] 모델 성능 개선을 위해 선택할 수 있는 요소 : compute budget, model size, dataset size (1) | 2023.09.03 |
| [Coursera] LLM에 필요한 효율적인 Multi-GPU 활용 전략 (1) | 2023.09.02 |
| [Coursera] LLM을 학습할 때 마주하는 문제점 (0) | 2023.09.02 |



