
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- paper review
- 코딩테스트실력진단
- 최단경로
- 그래프이론
- Coursera
- Scaling Laws
- Lora
- 완전탐색
- 이분탐색
- bfs/dfs
- Fine-Tuning
- peft
- 파인튜닝
- 스터디
- 플로이드와샬
- speaking
- 파이썬
- 판다스
- DP
- 머신러닝
- 알고리즘
- English
- 코드트리
- LLM
- Generative AI
- 코딩테스트
- Study
- 데이터분석
- 프로그래머스
- Python
- Today
- Total
생각하는 아져씨
Fine tuning 후 Model Evaluation(ROUGE, BLEU, Benchmarks) 본문
Fine tuning 후 Model Evaluation(ROUGE, BLEU, Benchmarks)
azeomi 2023. 9. 14. 11:00앤드류 응 교수님의 강의를 듣고 정리 및 공부한 글임을 알려드립니다.
Generative AI with LLMs In Generative AI with Large Language Models (LLMs), created in partnership with AWS, you’ll learn the fundamentals of how generative AI works, and how to deploy it in real-world applications.
지금까지 Pre-training과 Fine-tuning을 통해 모델의 성능을 높이는 방법을 공부했습니다.
사전학습 모델을 파인튜닝하면 더 나은 성능을 얻을 수 있음을 확인했는데, 그렇다면 어떻게 “성능 향상”을 얻었다고 확인할 수 있을까요?
이를 위해서 LLM이 전 보다 좋은 성능을 가졌음을 확인할 수 있는 메트릭이 필요합니다. 오늘은 모델의 성능을 평가하고 다른 모델과 비교할 때 사용할 수 있는 Metric에 대해서 공부해보려고 합니다.
LLM Evaluation의 Challenge
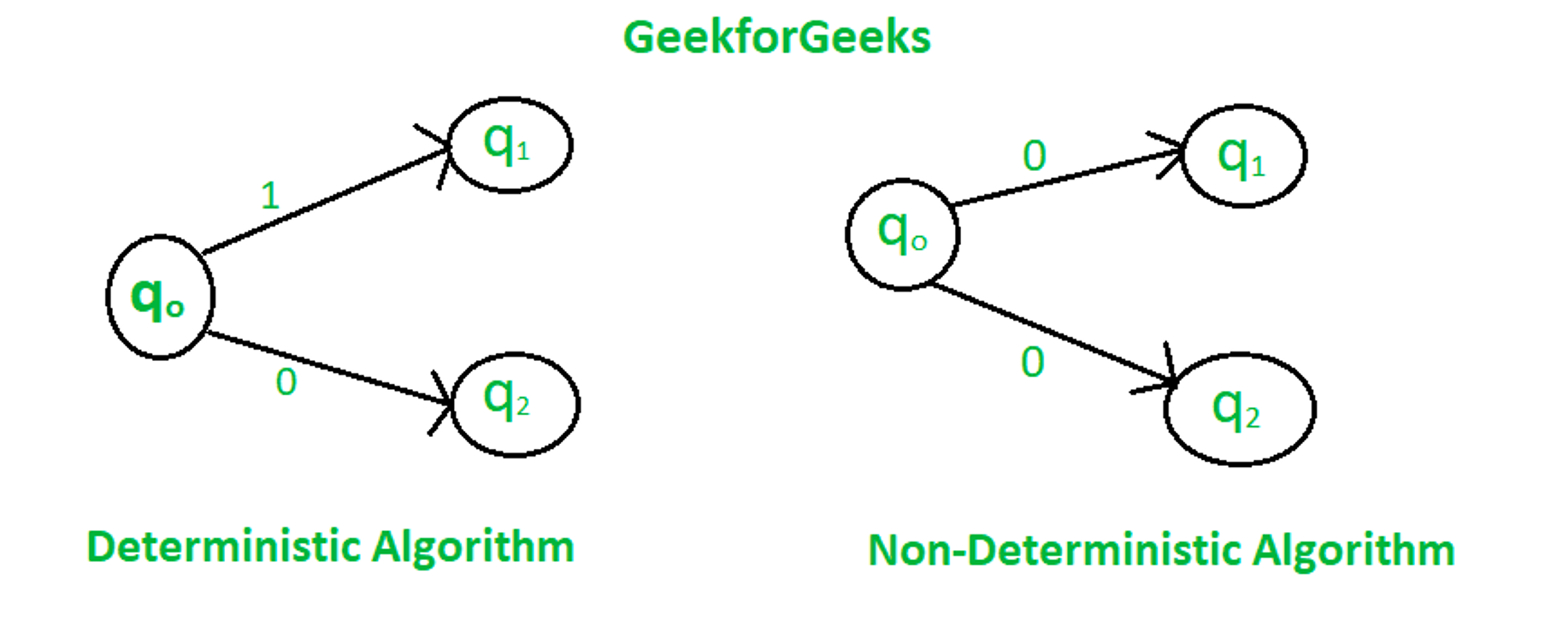
지금까지 전통적인 머신러닝에서는 모델의 성능을 측정하는데 Accuracy(정확도)을 사용했습니다.

이렇게 할 수 있었던 이유는, 머신러닝 모델이 deterministic 모델이기 때문입니다. → 맞추거나, 아니거나
하지만 이와 다른 Non-deterministic 모델, 예를 들어 언어 기반 모델은 맞추거나/아니거나로 판단할 수 없기 때문에 정확도를 측정하는 것이 매우 어렵습니다.
예시를 살펴봅시다.
- Mike really loves drinking tea : 마이크는 차 마시는 것을 너무 좋아한다.
- Mike adores sipping tea : 마이크는 차마시는 것을 사랑한다.
이 두 문장의 의미는 같습니다. 정확도 Metric으로 이 유사함을 측정할 수 있을까요?! 아쉽게도 측정하지 못합니다.
동일한 메커니즘으로, 유사하지 않은 정도도 측정할 수 없습니다.
- Mike dos not drink coffee : 마이크는 커피를 마시지 않는다.
- Mike does drink coffee : 마이크는 커피를 마신다.
이 두 문장의 차이는 비록 한 단어, ‘not’ 이지만, 두 문장의 의미는 완전히 다릅니다.
물론 사람은 두 문장의 유사도, 차이점을 알 수 있지만 모델이 만들어낸 수많은 출력과 문장들을 일일이 확인할 수 없기 때문에
자동적으로 구조화된 메트릭으로 측정할 수 있는 방법이 필요하게 됩니다. 이렇게 문장의 유사도, 차이점을 측정할 수 있는 방법에는 ROUGE와 BLEU가 있습니다.
최근에는 2가지 메트릭 외에도 다양한 메트릭이 등장하고 있습니다.
LLM Evaluation - Metric
ROUGE는 Recall Oriented Understudy for Jesting Evaluation을 말하는 것으로, 주로 자동 생성된 요약과 human-generated reference 요약을 비교 평가할 때 사용됩니다.
BLEU는 Bilingual Evaluation Understudy을 말하는 것으로, 기계번역 된 텍스트의 퀄리티를 평가하거나, 기계번역 텍스트와 human-generated translations를 비교할 때 사용됩니다.
이 2가지 메트릭의 공통점은 바로 ‘N-gram’을 사용해 평가한다는 것입니다.
N-gram
N-gram의 N에 따라서, unigram, bigram, n-gram으로 표현할 수 있습니다.

그럼 이 N-gram을 이용해서 어떤 원리로 측정하게 되는 것일지 살펴보겠습니다.
ROUGE-1,2,3,…N
ROUGE - N에서 N은 N-gram의 N을 나타냅니다. 즉 N=1 이라면 unigram만 본다는 것이고, N=2 라면, bigram을 보는 것입니다. N을 기준으로 생성된 출력과 정답 간의 얼마만큼의 단어를 맞췄는지를 Recall, Precision, F1-Score을 측정하는 방식입니다.
ROUGE-1은 unigram을 보기 때문에 개별 단어에 집중해서 계산합니다.

Recall의 경우, unigram in references는 레퍼런스에 존재하는 단어 수이기 때문에 4가 되고, unigram matches는 4개의 단어가 매칭되어서 4가 됩니다.
N=1일 경우, 개별 단어에 집중해 계산하기 때문에 단어의 순서는 고려하지 않는다는 단점이 존재하게 되는데요, 이는 의미가 다른데 점수가 똑같게 나오는 문제를 야기할 수 있습니다.
만약, It is cold outside와 It is not cold outside는 의미는 반대인데도 불구하고, 동일한 점수를 얻는 문제가 생겨버립니다.
이런 문제는 bigram으로 해결할 수 있습니다.
ROUGE-2는 bigram을 봄으로써, 문장 간의 bigram의 매칭될 가능성이 낮아지게 되면서 점수가 낮아지게 됩니다.
두 덩어리로 묶이면서 ROUGE-2의 Recall, Precision, F1 점수도 달라지게 됩니다.
계산해 보면,
- ROUGE-2 Recall = 0.67
- ROUGE-2 Precision = 0.5
- ROUGE-2 F1 = 0.57
이런 식으로 N을 늘려가면서 문장의 순서도 고려할 수 있는 ROUGE를 측정할 수 있습니다.
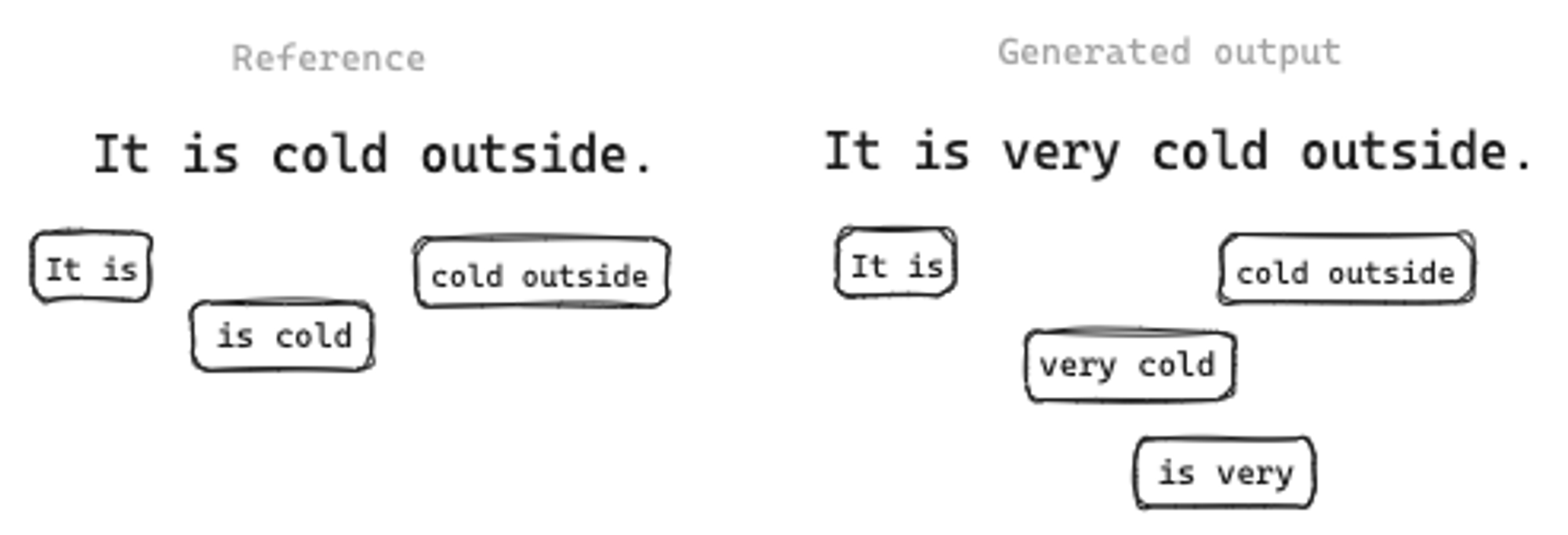
ROUGE-L
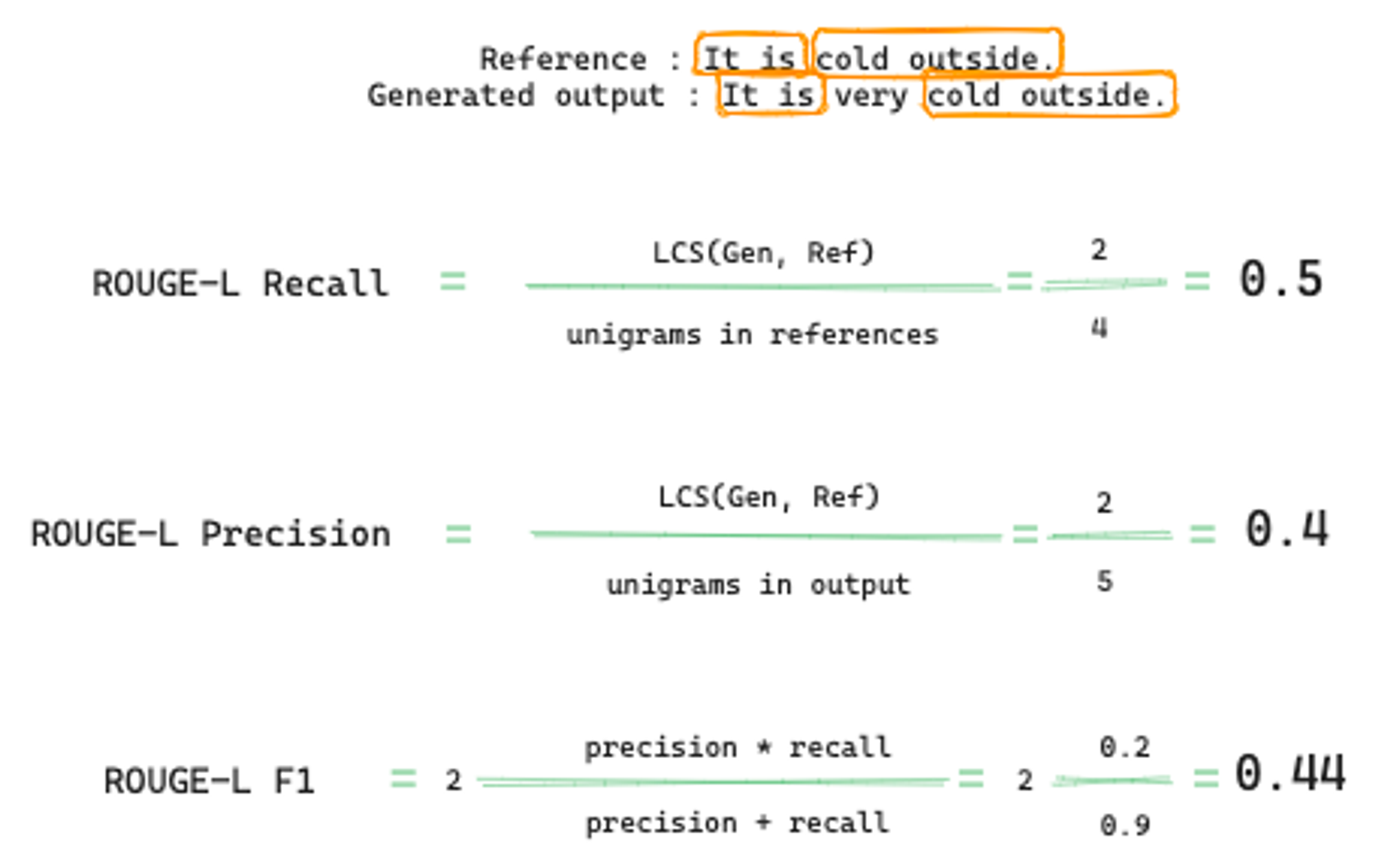
이와 비슷한데 또 다른 방법으로는 ROUGE-L이 존재합니다. 이는 References와 Generated output 간의 Longest common sequence(가장 긴 시퀀스)를 사용한 방법입니다.
위의 예시로 들자면,
- References와 Generated output의 LCS는 → (It is)와 (cold outside)입니다.
이걸 활용해서 ROUGE-L의 Recall, Precision, F1 점수를 구할 수 있죠!
ROUGE-Clipping
아직까지도 위의 방법들이 다 완벽하진 않습니다. 🤣 그래서 이를 해결하기 위한 다양한 방법이 아직 있는데 그중 하나가 Clipping입니다.
다음의 예시는 같은 단어가 반복되었음에도 불구하고 높은 점수를 받는 경우입니다.
Reference : It is cold outside.
Generated output : cold cold cold cold
👉 이때 ROUGE-1 Precision은 어떻게 될까요? 바로… 1입니다. 레퍼런스에 매칭된 단어가 4번이나 반복되었는데 최대점수인 1을 받는 것은 뭔가 이상합니다. 그래서 이경우를 Clipping 방법으로 해결할 수 있습니다.
Clipping : 일치하는 unigram의 수를 reference 내의 해당 unigram 수로 제한하는 것
그렇다면 위 예에서는 reference 내의 cold 수가 1개이므로, ROUGE- 1 Precision은 1/4로 0.25의 값을 갖게 됩니다.
이 밖에도 문장의 순서가 완전히 뒤바뀌었는데 단어는 매칭될 때 등과 같이, ROUGE 메트릭에는 한계가 여전히 존재하기 때문에
문장, 문장 사이즈, Use-case에 따라 다른 ROUGE를 사용해서 실험하는데 도움이 될 수 있도록 해야 합니다.
ROUGE 논문에 따르면 다양한 Metric을 살펴볼 수 있습니다. ☺️
BLEU
BLEU는 여러 N-gram size에 대해 평균 Precision을 측정합니다. References 번역과 Generated 번역 간에 얼마나 많은 N-gram이 일치하는지를 확인함으로써 평가합니다.
자세한 설명과 코드는 여기서 공부해 볼 수 있습니다. (논문)
BLEU도 ROUGE와 비슷하게 계산을 진행하면 됩니다. 대신 Precision의 평균입니다.
이처럼, ROUGE와 BLEU는 매우 간단한 메트릭으로 계산 비용이 저렴합니다. 보통 ROUGE는 Summarization Task에, BLEU는 Translation Task에 많이 사용되곤 합니다.
하지만 여러 도메인에서 많은 Task를 수행하는 LLM의 성능을 최종 평가하기에는 ROUGE와 BLEU를 단독으로 사용할 수는 없습니다.
그래서 모델의 성능을 전반적으로 평가하기 위해 많은 연구자들이 평가 Benchmarks(기준)을 개발했고 이를 활용해서 LLM의 성능을 확인해 볼 수 있습니다.
Benchmarks
많은 연구자들이 복잡한 LLM을 총체적으로 비교/평가하기 위해서 특별히 벤치마크를 개발했고 이를 활용했습니다.
다양한 LLM 논문의 Experiment 부분에서 여러 벤치마크를 확인할 수 있었을 텐데요!
대표적으로 다음의 Evaluation Benchmarks가 있습니다.
Evaluation Benchmarks
이 벤치마크들은 광범위한 Task와 시나리오를 다룸으로써 LLM의 특정한 측면들을 테스트할 수 있습니다.
- GLUE(General Language Understanding Evaluation)
- 2018년 도입
- sentiment-analysis, question-answering(QA) 같은 자연어 태스크 모음
- 모델이 다양한 태스크에 일반화될 수 있도록 장려하기 위해 만들어짐.
- SuperGLUE
- GLUE의 후속버전, 2019년 도입
- GLUE에 포함되지 않은 태스크를 포함
- multi-sentence reasoning, reading comprehension
- GLEU와 SuperGLUE 둘 다 모델을 비교해 볼 수 있는 리더보드가 존재.
- MMLU(Massive Multitask Language Understading)
- 최신 LLM을 위해 설계되었음.
- LLM이 잘 수행되기 위해서는, 초등수학, 미국역사, 컴퓨터과학, 법률 등에 대한 광범위한 세계지식과 문제 해결능력이 있어야 하는데 이를 평가한다.
- Big-bench
- 언어학, 아동발달, 수학, 상식추론, 생물학, 물리학, 사회적 편견, 소프트웨어 개발 등 204개의 Task로 구성
- 3가지의 다른 사이즈로 제공된다.
- HELM(Holistic Evaluation of Language Models)
- 모델의 투명성을 개선하고 특정 Task에 적합한 모델에 대한 지침을 제공하고자 함.
- multi metric 접근 : 16가지 핵심 시나리오에 걸쳐 7가지 metric을 측정
- F1 score의 Precision 같은 basic accuracy 측정값을 넘어서는 메트릭을 평가 → fairness, bias, toxicity 등. 이는 LLM이 잠재적으로 유해한 행동을 보일 수 있게 됨에 따라 중요성이 더욱 커질 것이다.
LLM이 벤치마크에 대해서는 인간만큼 잘하긴 하지만, 일반적으로 아직까진 인간처럼 동작하지는 않습니다.
그래서 LLM의 새로운 속성과 벤치마크 사이에서 서로 더 잘 생성하고 평가할 수 있는 것들이 나오고 있습니다. AI Arm race가 벌어지고 있는 것이죠 ☄️
인간의 행동과 생각을 수학으로 표기해서 평가한다는 것이 상당히 어려운데 앞으로 어떤 벤치마크와 Metric이 나올지 궁금해집니다.
'Machine & Deep Learning > Generative AI' 카테고리의 다른 글
| PEFT, LoRA 입문하기✌️ (0) | 2023.10.20 |
|---|---|
| 파라미터를 효율적으로 파인튜닝한다?! 🤩 (1) | 2023.10.20 |
| Instruction Fine-tuning과 Catastrophic Forgetting (0) | 2023.09.13 |
| Fine-tuning - Instruction Fine-tuning에 대해서 (0) | 2023.09.12 |
| [Coursera] 도메인을 고려한 사전학습과 BloombergGPT (0) | 2023.09.04 |



