
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 이분탐색
- 스터디
- Scaling Laws
- 코드트리
- 코딩테스트
- English
- peft
- paper review
- Coursera
- 그래프이론
- Python
- Generative AI
- 파인튜닝
- bfs/dfs
- DP
- Study
- 프로그래머스
- Fine-Tuning
- 플로이드와샬
- 파이썬
- 데이터분석
- 알고리즘
- LLM
- 머신러닝
- 최단경로
- 코딩테스트실력진단
- 완전탐색
- Lora
- 판다스
- speaking
Archives
- Today
- Total
생각하는 아져씨
Training Compute-Optimal Large Language Models 리뷰 본문
Machine & Deep Learning/NLP Paper
Training Compute-Optimal Large Language Models 리뷰
azeomi 2023. 9. 8. 15:54오늘은 귀여운 친칠라 논문에 대해 리뷰해보겠습니다.

1. Introduction
- 최근 5000억개의 파라미터를 가지는 LLM이 많이 공개되었다. 또한 Large Autoregressive 트랜스포머 모델들은 Zero-shot, Few-shot, Fine-tuning 같은 프로토콜을 활용해 다양한 task에서도 좋은 성능을 보여주고 있다.
- 이런 LLM을 학습시키는데 상당한 컴퓨팅 예산이 들기 때문에, 모델 사이즈에 따른 컴퓨팅 비용을 고려해야 한다. 더군다나 이렇게 큰 모델은 현실적으로 1번 정도 학습할 수 있기 때문에 주어진 컴퓨팅 예산 안에서 최적의 모델을 정확하게 평가할 수 있는 것이 매우 중요하다.
- Kaplan et al.(2020)의 논문에서 이 문제에 대해 다뤘다. 모델의 파라미터 수와 성능의 관계에는 power law가 있음을 보여주었다. 즉, 모델이 크면 클수록 성능이 향상된다는 결과를 보여줬다.
- Kaplan et al.(2020)에서 주목할 만한 결론은, 최적의 계산을 위해 large model을 가능한 한 낮은 손실을 갖도록 학습해서는 안된다는 것이다. 즉, 가장 낮은 loss를 얻을 때 까지 모델을 학습한다면 좋은 성능을 보일 수 있겠지만, 컴퓨팅 비용은 증가하기 때문에 최적의 계산이라고 볼 수 없다는 것이다.
- 본 논문에서도 같은 결론에 도달했지만 , large model은 Kaplan et al.(2020)의 저자들이 권장하는 것보다 훨씬 더 많은 training tokens에 대해 학습해야 한다는 것을 알아냈다.
- Kaplan et al.(2020)과 달리, 모델 사이즈와 학습 토큰 수는 동일한 비율로 확장되어야 함을 알아냈다.

표에서 볼 수 있듯이,
- Kaplan et al.(2020)과 GPT-3의 set-up을 가지는 Large model은 약 3000억개의 토큰을 학습하고 모델 사이즈(=파라미터 수)를 증가시키는 접근 방식을 택함으로써 컴퓨팅 비용을 소모.
- 여기서 질문 “Given a fixed FLOPs budget, how should one trade-off model size and the number of training tokens?”
- Final pre-training loss L(N, D)를 통해 질문에 답하고자 했다.
- N(모델 파라미터 수), D(학습 토큰 수)
- 컴퓨팅 예산인 C 는 deterministic function → FLOPs(N, D), 주어진 N과 D에 따른 컴퓨팅 비용
- FLOPs(N, D) = C 인 상태에서, loss L을 최소화 하고자 했다.
- 이를 통해 최적의 모델 사이즈(N_opt(c)), 학습 토큰 수(D_opt(C))를 구하고자 한다.
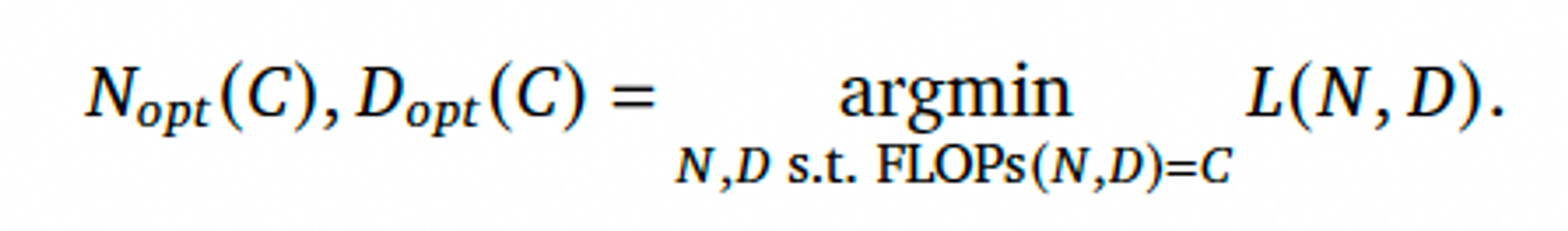
이 함수를 70M~16B개의 파라미터, 5B~400B개의 학습 토큰을 가지는 400개 이상의 모델을 기반으로 추정했다. 그 결과, Kaplan et al.(2020)과는 상당히 다른 결과를 얻을 수 있었다.
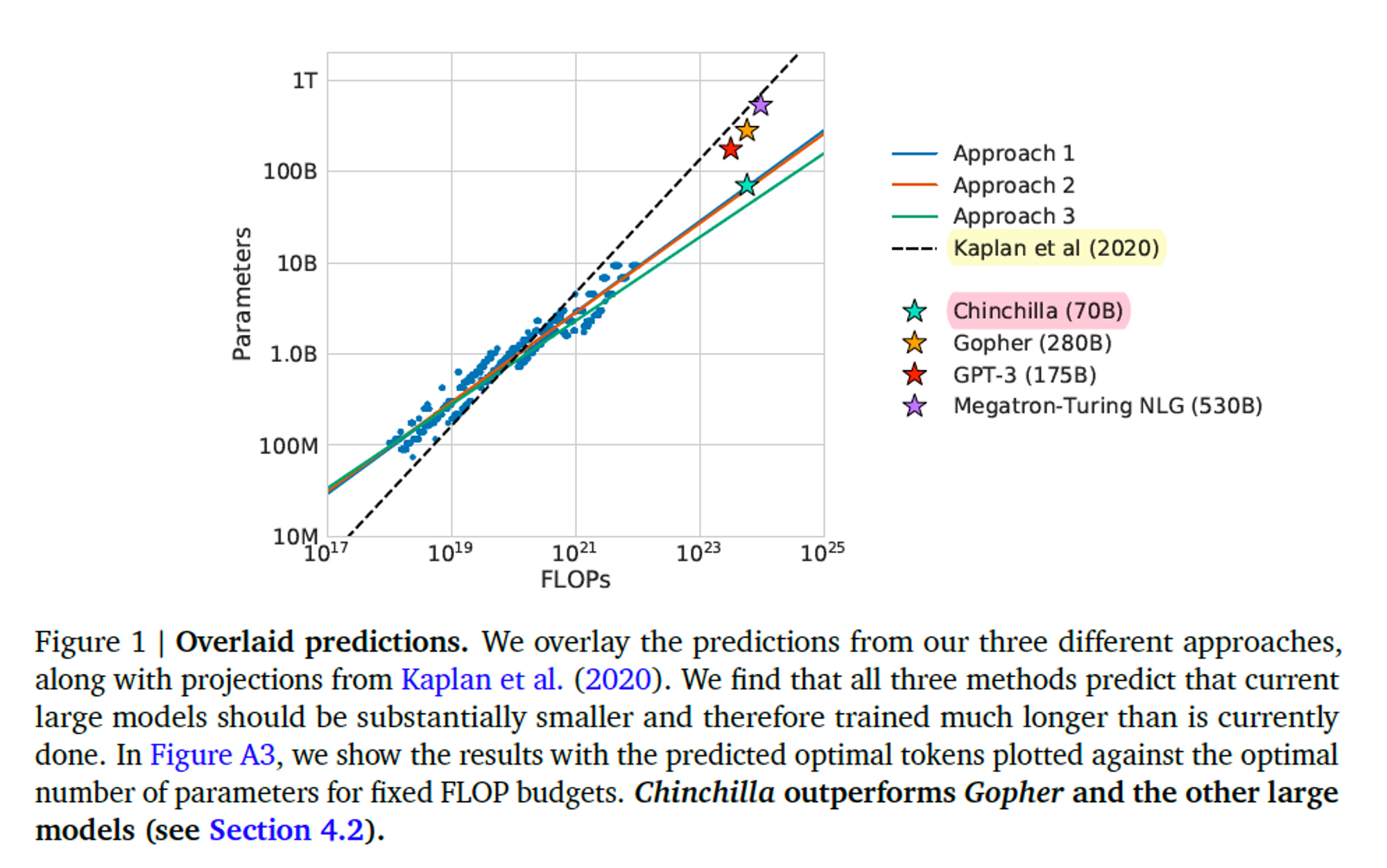
그림을 통해 얼마나 다른지 확인할 수 있다.
- 본 연구에서 추정한 최적의 컴퓨팅 경계(compute-optimal frontier)는 Approcah 1, 2, 3을 나타낸다. 하지만 Gopher의 경우, Gopher를 학습하는데 사용되는 컴퓨팅 예산의 경우 최적의 모델은 4배 더 많은 토큰을 학습하면서 4배 더 작아야 함을 알 수 있다.
- 이를 검증하기 위해, Chinchilla 모델을 설계해 70B 파라미터 & 1조 4천억 토큰을 가지는 더욱 최적의 모델을 얻을 수 있었다. → Gopher 보다 뛰어난 성능은 물론 Inference 시 추론 비용이 크게 줄어드는 효과.
- 게다가 이는 fine-tuning 시 에너지 비용도 감소시킬 수 있는 효과.
즉, Kaplan et al.(2020)과 GPT-3의 방식을 따르는 모델들은 모델 크기에 비해 충분한 학습을 하지 못했다는 결론을 얻을 수 있다.
2. Related Work
- LLM은 좋은 성능을 보여주었지만, 아직 몇가지 난제가 존재한다. 그 중 하나가 컴퓨팅 비용에 대한 문제이다. 모델 사이즈가 커질 수록 성능이 개선되었지만 이는 학습 및 추론에 대한 컴퓨팅 비용도 증가 시키는 단점이 있다. 👉 본 연구에서 모델을 확장할 수 있는 Key point로 크고, 질이 좋은 학습데이터를 사용하는 방법을 검증했다.
- 이미, Kaplan et al.(2020), 모델 사이즈와 성능(loss)에 대한 관계를 연구했고 주어진 컴퓨팅 예산에서 최적의 모델 사이즈를 선택하는 것을 소개했다. 👉 본 연구에서도 유사한 question을 다뤘지만, 다른 결과를 얻었다. 그 이유는.
- 첫번째, Kaplan et al.(2020)은 고정된 학습 토큰 사이즈, learning rate schedule을 사용했다. 이렇게 하면, 하이퍼파라미터가 loss에 미치는 영향을 모델링 할 수 없게 된다. 반대로 본 연구에서는, learning rate schedule을 학습 토큰 수에 거의 매칭되도록 설정해서 모델 사이즈에 관계 없이 최종 loss가 좋은 것으로 나타났다.
- 결국, 컴퓨팅 예산이 증가함에 따라 모델 사이즈가 학습 데이터의 사이즈 보다 훨씬 더 빠르게 증가해야 한다는 결론에 도달하게 된다.
- 하지만 본 연구에 따르면, 두개의 요소(model size, dataset size)는 같은 비율로 확장되어야 한다.
- 두번째, Kaplan et al.(2020)은 본 연구보다 작은 모델, 대부분 100M 미만 파라미터 모델을 사용했지만, 본 연구는 최대 16B 파라미터를 가지는 모델을 포함했다. 왜냐면 FLOP-loss 경계선에 약간의 곡률이 있었기 때문에.

3. Estimating the optimal parameter, training tokens allocation
- 본 연구의 question을 다시 상기시키면 다음과 같다.
- “Given a fixed FLOPs budget, how should one trade-off model size and the number of training tokens?”
- 이 질문에 답하기 위해 3가지 Approach을 제시했다.
- 결론부터 말하자면, 3가지 방법에 대해 비슷한 결과를 도출했고, 모두 모델 파라미터 수와 학습 데이터 토큰 수는 반드시 동일하게 확장되어야 한다는 결론에 도달했다.

3.1. Approach 1 : Fix model sizes and vary number of training tokens
- 고정된 사이즈의 모델들에 대해 training steps를 변경하여 각 모델을 서로 다른 4개의 학습 시퀀스로 학습을 진행했다. → 주어진 학습 FLOPs에 대해 최소 손실의 추정치를 얻을 수 있다.
- 파라미터 수 N 개인 서로 다른 4개의 모델을 학습하고, range 가 16x 인 horizon 에 대하여 learning rate 를 10x 씩 감소시켰다.
- 각 실행마다, training loss curve를 smooth한 뒤 interpolate를 진행했다. → 각 실행에 대한 FLOPs 수에서 training loss까지 continuous mapping을 얻을 수 있다.
- 그런 다음, 각 FLOPs 수에 대해 어떤 실행이 가장 낮은 loss를 달성했는지 결정한다.
- 이러한 interpolation을 사용해서, FLOPs(N, D) = C를 얻을 수 있다.
- FLOPs 수 ‘C’ 에서, 가장 효율적인 모델 크기 N과 학습 토큰 수 D에 대한 매핑.
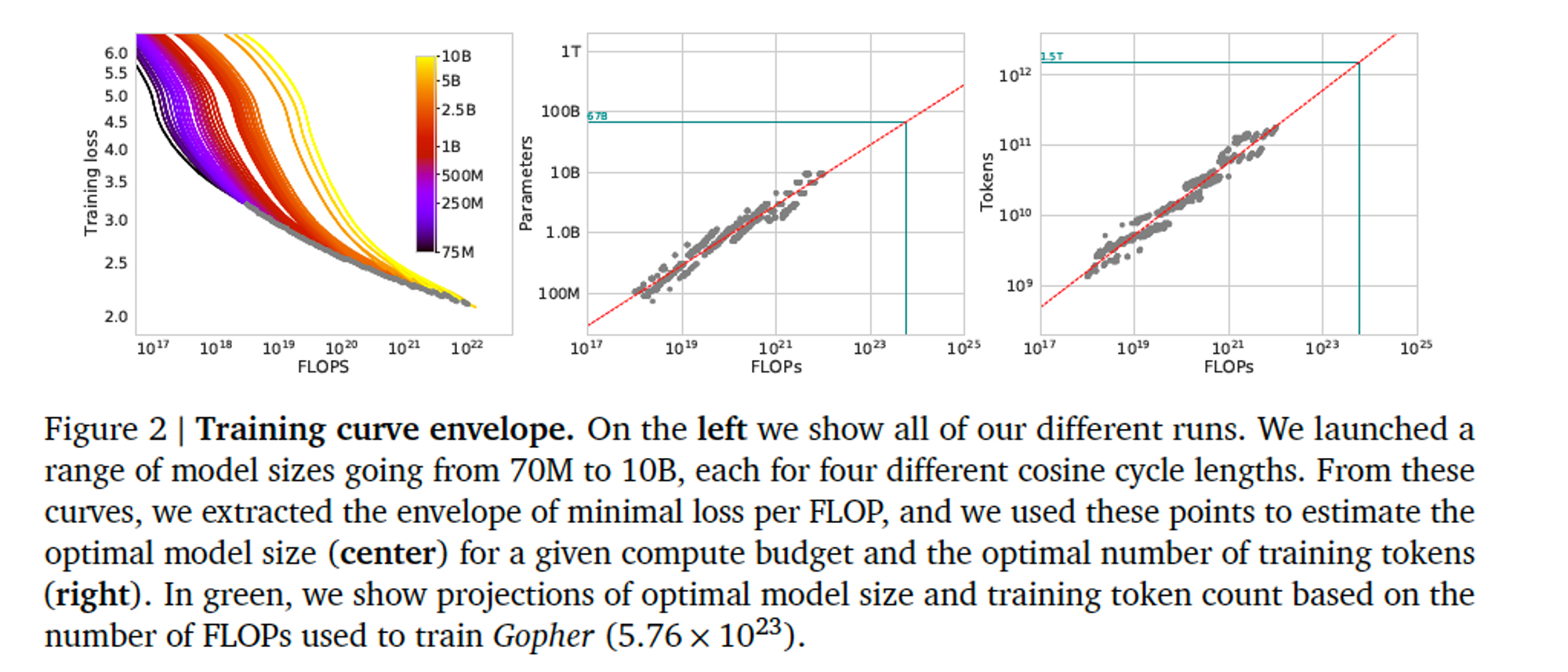
- 주어진 Compute budget에 따른 최적의 모델 사이즈와 학습 토큰 수에 대한 관계를 얻었다. 𝑁_{𝑜𝑝𝑡} \propto 𝐶^𝑎 \ and\ 𝐷_{𝑜𝑝𝑡} \propto 𝐶^𝑏 에 따라서, a = 0.50, b = 0.50 임을 확인했다.
3.2. Approach 2 : IsoFLOP profiles
- 9개의 서로 다른 학습 FLOPs 수의 고정된 세트에 대해서 모델 사이즈를 변경하여 각 point마다 final training loss를 고려했다.
- (N, D, L)을 고려한 Approach 1과 달리, Approach 2는 다음의 질문에 답할 수 있다. ” For a given FLOP budget, what is the optimal parameter count(=최적의 모델 크기)?”
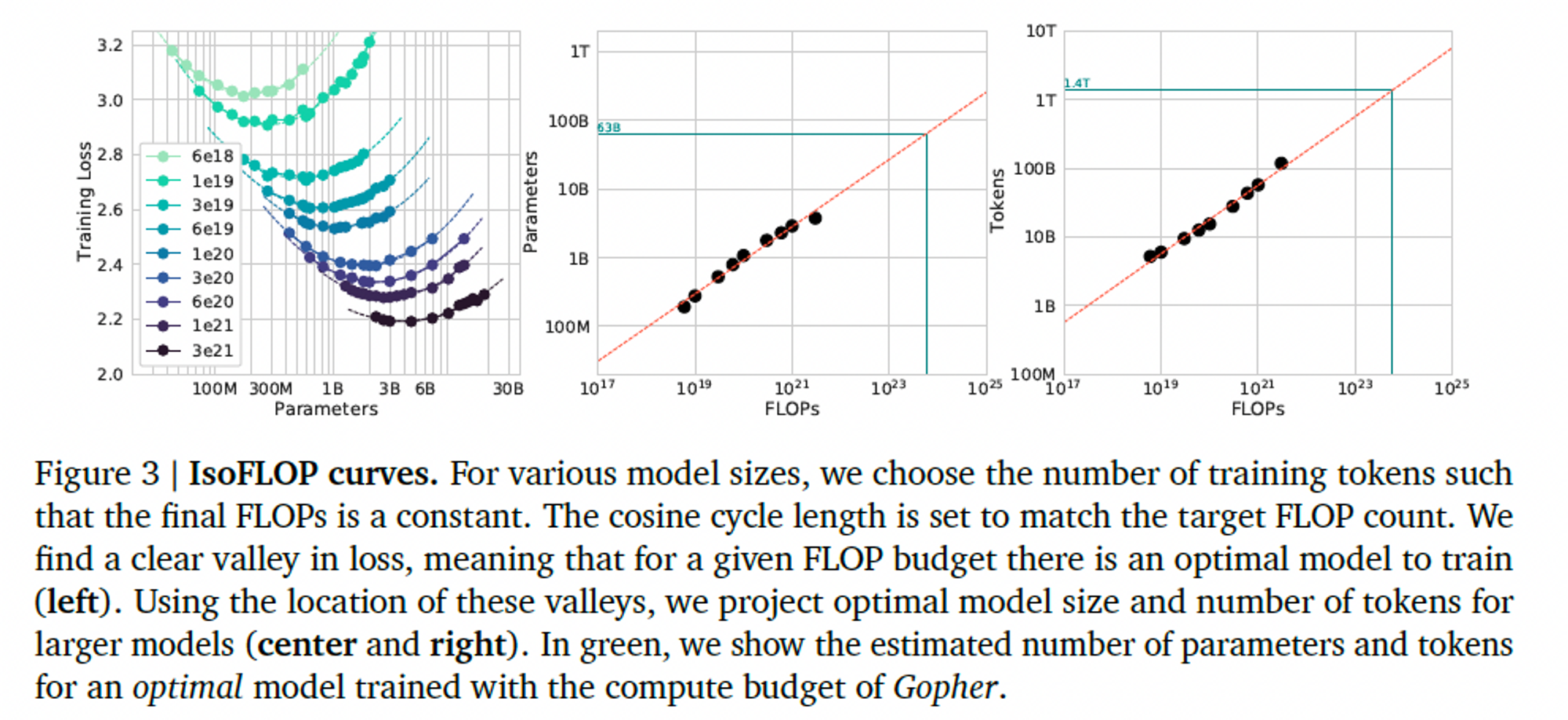
- 왼쪽 : 각 FLOPs 예산에 대해 파라미터 수에 대한 smoothing이 된 final loss를 plot 한 것으로, 포물선에 맞춰 최소 손실을 달성하는 모델 사이즈를 추정했다.
- 이전과 마찬가지로, FLOPs와 최적의 손실을 갖는 모델 사이즈 & 학습 토큰 수 사이의 관계를 구했더니,
- $𝑁_{𝑜𝑝𝑡} \propto 𝐶^𝑎 \ and\ 𝐷_{𝑜𝑝𝑡} \propto 𝐶^𝑏$ 에 따라서, a = 0.49, b = 0.51 임을 확인했다.
3.3. Approach 3 : Fitting a parametric loss function
- Approach 1, 2에서 발생한 모든 Final loss들을 model parameter 수와 number of seen tokens로 모델링했다.
- 다음의 함수 형태를 제안했다.
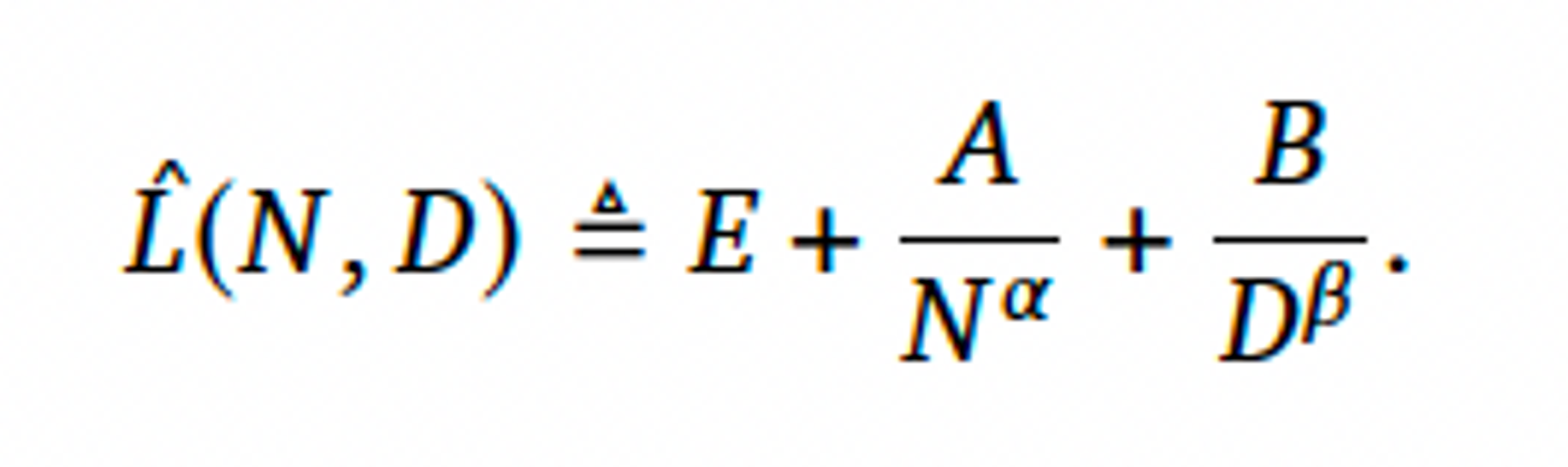
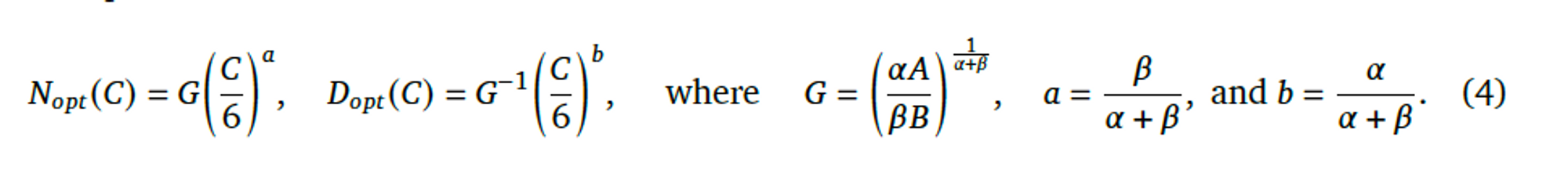
- 첫번째 Term : 데이터 분포에 대한 이상적인 generative process의 loss를 capture → natural text의 엔트로피와 일치해야 한다.
- 두번째 Term : 완벽하게 학습된 N개의 파라미터의 트랜스포머가 이상적인 generative process에 비해 성능이 떨어진다는 사실을 capture
- 세번째 Term : 트랜스포머가 수렴하도록 학습되지 않았다는 것을 capture, 데이터셋 분포의 sample에 대해 한정된 수의 최적화 단계만 수행했기 때문에.
- 이 방식을 통해서 a = 0.46, b = 0.54 임을 확인했다.
3.4. Optimal model scaling
- 3가지 Approach를 통해서 서로 다른 학습된 모델을 사용함에도 불구하고, 모델 parameter, token의 optimal scaling에 대해 비슷한 예측 결과를 도출함을 확인했다.
- 3가지 모두, Compute budget이 증가함에 따라 모델 크기와 학습 데이터의 양을 거의 비슷한 비율로 늘려야 한다는 것을 시사한다. → Table 2에서 확인 가능.
- Table 3, 주어진 computing-optimal frontier에 놓일 수 있도록 보장하는 예상 FLOPs와 토큰 수를 볼 수 있다.

- 더욱이 이는 현재 많은 LLM이 over-sized 되었음을 암시한다.
4. Chinchilla
- 섹션 3 분석에 따르면, Gopher의 컴퓨팅 예산을 위한 최적의 모델 크기는 40 ~ 70B 파라미터이다.
- 본 연구는 위 분석에 따라, 1.4T 토큰에 대해 70B 파라미터로 모델을 학습해서 이 가설을 확인했다.
- 그것이 바로 Chinchilla(친칠라) 라는 모델이고, Gopher 및 기타 LLM과 비교해봤다.

다음의 Task에 대해 평가를 진행했다.
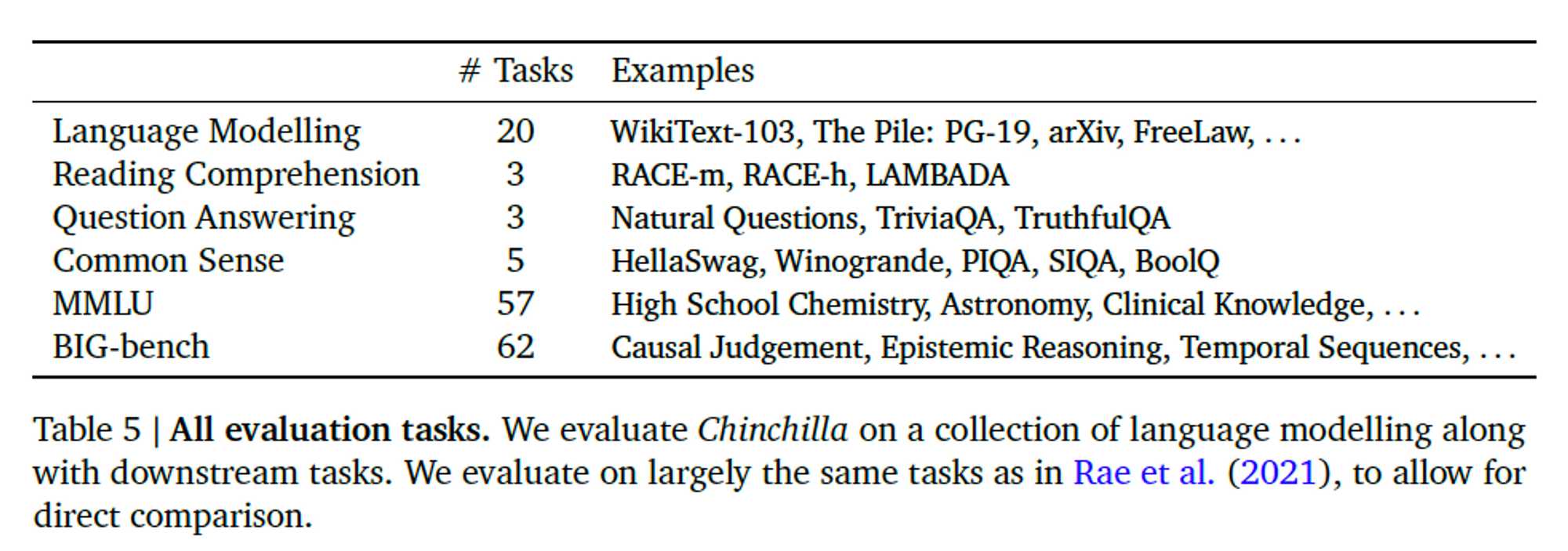
실험 결과, Chinchilla는 The Pile의 모든 하위집합에 대해서 Gopher를 크게 능가했다.

MMLU(Massive Multitask Language Understanding) 벤치마크에 대해서도, Chinchilla는 Gopher 보다 훨씬 작은데도 불구하고 성능을 뛰어넘었다.
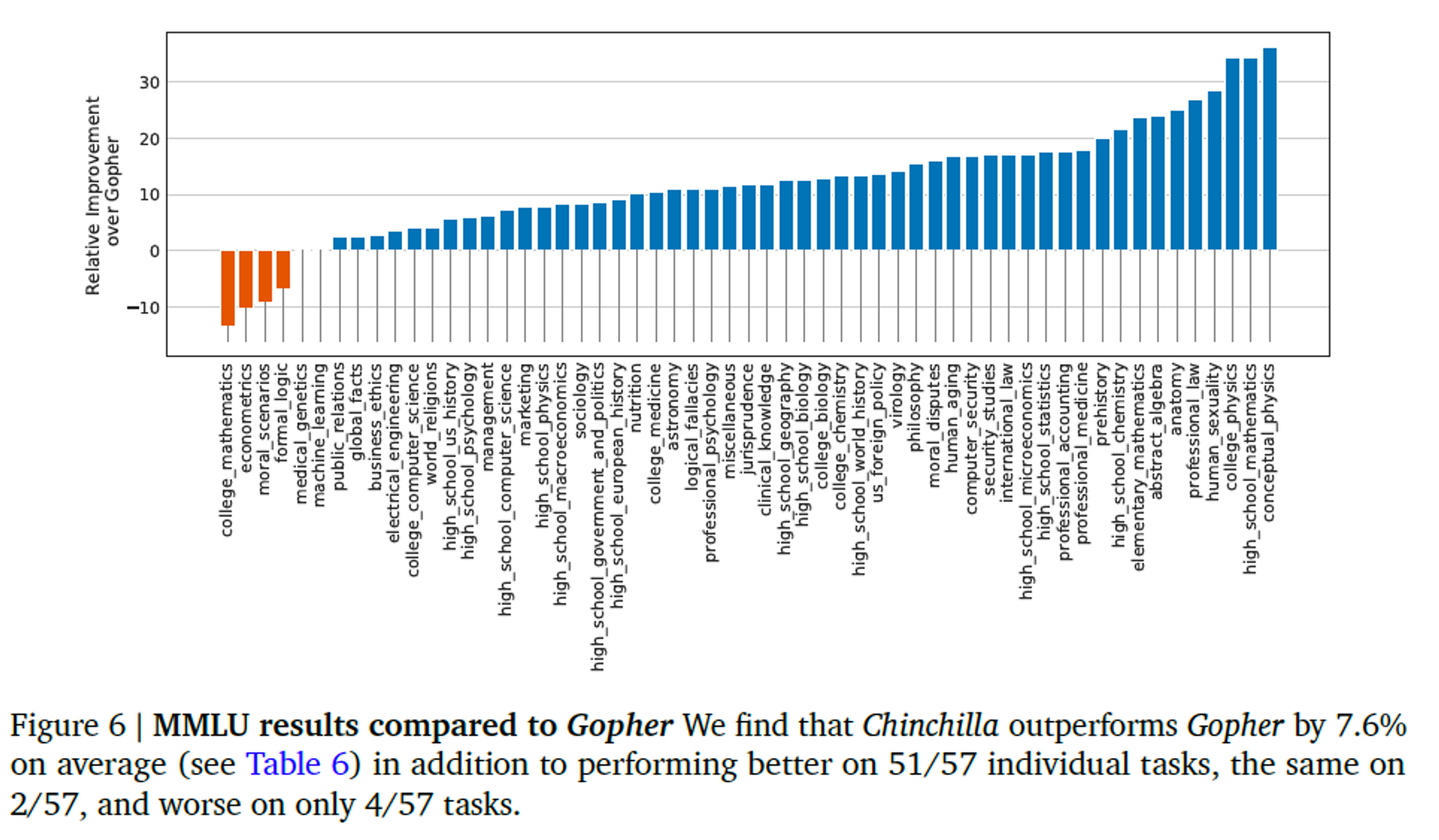
5. Discussion & Conclusion
- 한동안 LLM의 트렌드는 모델 사이즈를 증가 시킴으로써 좋은 성능을 얻는 것이었다. 이렇게 메가 모델을 양성하려는 열망은 상당한 엔지니어링 innovation을 가져왔지만, 이렇게 더 큰 모델을 학습시키려는 경쟁이로 인해 동일한 Compute budget으로 달성할 수 있는 모델에 비해 현저히 성능이 떨어지는 모델이 발생할 것이라 생각했다.
- 그래서 모델 크기와 학습 기간을 최적으로 설정하기 위한 3가지의 Approach을 설정하고 실험해보니, Gopher가 over-sized 되었고 그것보다 더 작은 모델이 더 좋은 성능을 낼 수 있음을 확인했다. (친칠라)
- 대규모 언어 모델을 학습하는 데는 진전이 있었지만, 모델 성능을 보장하기 위해 데이터 세트 확장에 더욱 중점을 둘 필요가 있다. 대규모 데이터 세트는 책임감 있는 데이터 수집과 품질 보증을 강조하는 고품질의 데이터 세트일 때 유용하다.
- 특히, Chinchilla와 Gopher가 편향성에 취약했던 것 처럼 유해한 언어, 편견, 개인 정보가 포함되지 않은 질 좋은 데이터를 사용함을 권한다.
- 마지막으로, 논문은 auto-regressive 언어 모델에 대해서 실험을 진행했지만, 다른 형태의 모델로도 확장되기를 기대한다.
Reference
[Paper Review] Training Compute-Optimal Large Language Models (NeurIPS 2022)
[Paper Review] Democratizing Large Language Models : From 175B to 7B
'Machine & Deep Learning > NLP Paper' 카테고리의 다른 글
| [Paper] Are Large Pre-Trained Language Models Leaking Your Personal Information? (3) | 2023.02.15 |
|---|---|
| [Paper] A Neural Probabilistic Language Model (0) | 2022.09.01 |
'Machine & Deep Learning/NLP Paper' Related Articles
more

