
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 코드트리
- LLM
- Generative AI
- 코딩테스트실력진단
- paper review
- Fine-Tuning
- 알고리즘
- Study
- 머신러닝
- bfs/dfs
- 최단경로
- Coursera
- Scaling Laws
- 파이썬
- speaking
- 코딩테스트
- 그래프이론
- 완전탐색
- 판다스
- English
- 이분탐색
- Python
- DP
- 스터디
- 파인튜닝
- peft
- 프로그래머스
- Lora
- 플로이드와샬
- 데이터분석
- Today
- Total
생각하는 아져씨
[Paper] A Neural Probabilistic Language Model 본문
[Paper] A Neural Probabilistic Language Model
azeomi 2022. 9. 1. 22:51
2003년 논문으로 지금 최신 논문들을 나오게 한 흐름에 있는 논문입니다.
그때 당시 컴퓨팅 파워가 지금보다 좋지 않기 때문에 퀄리티 있는 실험은 진행하지 못했다고 합니다.
이 논문의 핵심은 실험 부분 보다 방법론이 중요하므로, 방법론 위주로 살펴보았습니다.
느낀점
저는 논문을 읽을 때 한번에 이해하자 보다는 먼저 1회독을 한 후에 그 다음부터 모르는 것을 살펴보면서 논문을 이해해야겠다 주의 입니다.
주로 2016년 이후의 최신 논문만 읽어오다가 2003년에 나온 논문을 읽으면서 느낀점은 제가 기초가 정말 부족하다는 것이었습니다.
내가 왜 최신 논문의 "어떤 부분"을 이해하지 못했는지 알았습니다. 그건 바로 기본기가 없었기 때문이죠...🤣
그래서 이 논문은 다시 한번 저의 NLP 지식 부족에 대한 경각심을 일깨워줬습니다.
여러 똑똑한 분들의 글들을 보면서 참고하여 제가 이해할 수 있도록 내용을 정리했습니다.
참고링크는 페이지 밑에 표시해두었습니다 :)
들어가기 전
본 논문은 Statistical Language Model의 단점을 해결하기 위해 Neural Probabilstic Language Model을 제안합니다.
그래서 Language Model 관련된 개념을 익힌 후 본 논문이 제안한 기술이 무엇인지 정리해보았습니다.
1. Language Model
- 언어모델(LM)이란 언어를 모델링하고자 단어 시퀀스(문장)에 확률을 할당하는 모델
- 이전 단어들이 주어졌을 때 다음 단어를 예측

비행기를 ~? 다음에 나올 단어를 선택하려고 할 때,
우리는 우리 지식에 기반하여 나올 수 있는 여러 단어들을 후보에 놓고 놓쳤다는 단어가 나올 확률이 가장 높다고 판단합니다.
그렇다면 기계에게 위 문장을 주고, '비행기를' 다음에 나올 단어를 예측해보라고 한다면 과연 어떻게 최대한 정확히 예측할 수 있을까요?

기계도 비슷합니다. 앞에 어떤 단어들이 나왔는지 고려하여 후보가 될 수 있는 여러 단어들에 대해서 확률을 예측해보고 가장 높은 확률을 가진 단어를 선택합니다.
이렇게 단어 시퀀스에 확률을 할당해 다음 단어를 예측하도록 하는 모델이 언어모델 입니다.
흔히 확인할 수 있는 언어모델 사용 예제는 '검색엔진' 입니다.
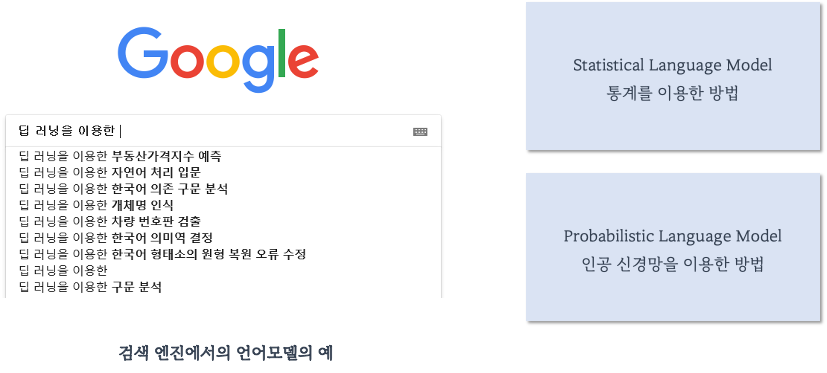
또한 언어모델은 통계를 이용한 방법과 인공 신경망을 이용한 방법으로 나뉠 수 있습니다.
1-1. Statistical Language Model
- 통계적 언어모델(SLM)은 기본적으로 count-based 접근하여 단어를 예측
- 문장이 발생할 확률을 조건부 확률의 Chain Rule로 나타낼 수 있음.
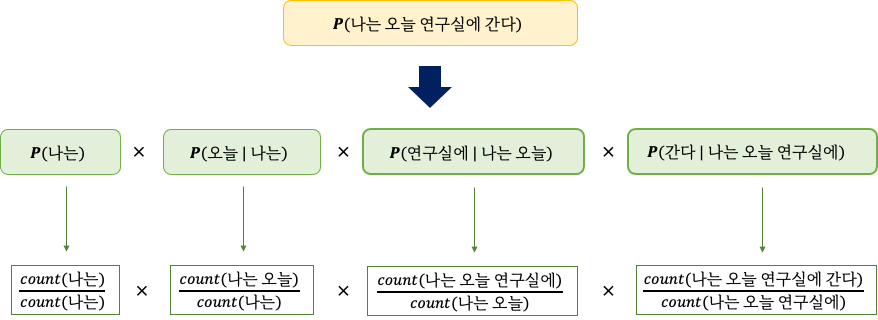
예를 들어 나는 오늘 연구실에 간다 문장이 있다고 해봅시다.
"나는 오늘 연구실에 간다" 라는 문장이 나타날 확률을 구할 때,
'나는', '오늘 | 나는', '연구실에 | 나는 오늘', '간다 | 나는 오늘 연구실에' 각각이 나타날 확률을 곱함으로써 구할 수 있습니다.
식은 다음과 같습니다.
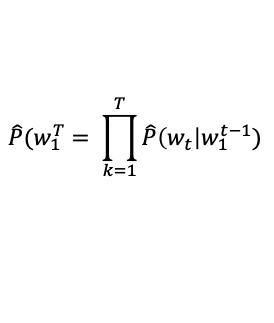
만약, 학습 데이터셋에 등장하지 않을 가능성이 있는 문장이 있다면 어떨까요?
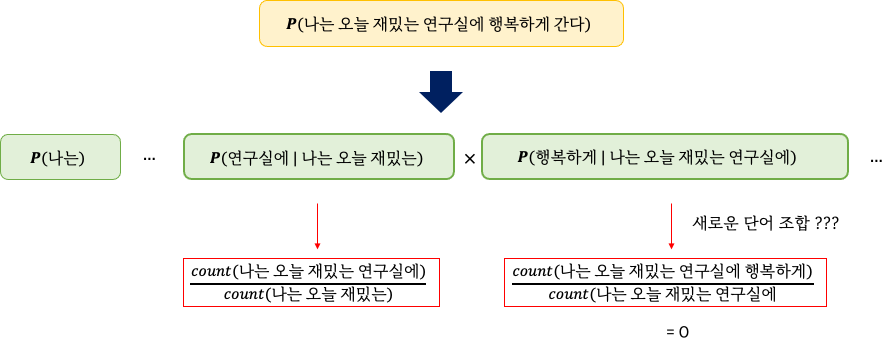
예를 들어 나는 오늘 재밌는 연구실에 행복하게 간다 는 문장이 있다고 해봅시다.
"나는 오늘 재밌는 연구실에 행복하게 간다" 라는 문장이 나타날 확률을 구할 때,
학습 데이터셋에서 보지 못한 새로운 단어 조합이 있을 경우 count는 0이 되고 따라서 Chain Rule에 의해 전체 문장의 확률이 0이 되게 됩니다.

따라서 Sparsity Problem 때문에 문장이 나타날 확률을 학습 데이터셋으로부터 추정하기가 어려워집니다.
그래서 근사하는 방법을 택했는데요, 이것이 n-gram 입니다.
1-2. N-gram Model
- 통계적 접근을 사용하는 SLM의 일종
- 모든 단어를 고려하는 것이 아닌 일부 단어만 고려
- n-gram: n개의 연속적인 단어 나열을 의미
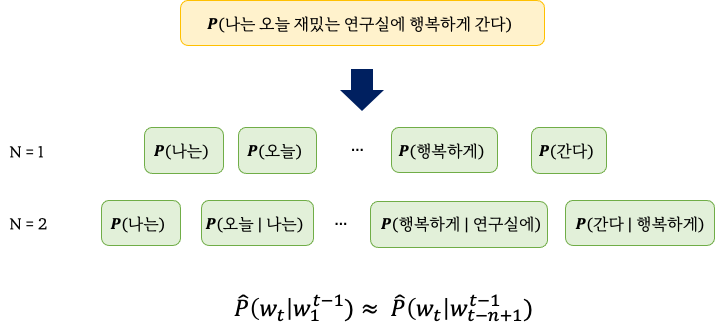
[5] N-gram은 각각의 단어들이 주변 단어에 조금 더 큰 영향을 받는다는 가정 하에,
마지막 n개의 단어로 부터 얻는 조건부 확률값이 전체 단어로 부터 얻는 조건부 확률값과 거의 같다는 것을 전제로 조건부 확률을 계산합니다. 상대적으로 짧은 시퀀스를 계산하기 때문에 out-of-sample에 조금 덜 민감해 질 것이며 계산 효율성도 상대적으로 좋습니다.
하지만 N-gram이라고 해서 Sparsity Problem이 해결되는 것은 아닙니다.

이를 해결하기 위해, Laplace Smoothing, Backoff Model, Interpolated Model 등의 방법이 있습니다.
1-3. Discrete representation VS Distributed Representation
N-gram을 포함한 기존 연구에는 해결해야할 문제가 있습니다.

1번의 경우
n을 작게 선택하면 훈련 코퍼스에서 카운트는 잘 되겠지만 근사의 정확도는 현실의 확률분포와 멀어집니다. 그렇기 때문에 적절한 n을 선택해야 합니다. 앞서 언급한 trade-off 문제로 인해 정확도를 높이려면 n은 최대 5를 넘게 잡아서는 안 된다고 권장되고 있습니다.
2번의 경우
Discrete word representation으로 인한 문제가 발생하고 이것이 바로 Language Model을 어렵게 만든 차원의 저주 입니다.
1-3-1. Discrete Representation : One-hot encoding
[Discrete Representation의 첫번째 단점]
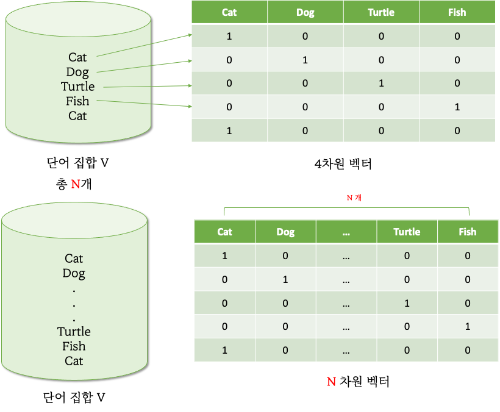
One-hot encoding은 각 단어를 단어집합 개수와 동일한 차원 수로 임베딩을 하게 되는데 이 때 단점은 단어 집합의 개수가 아주 클 때 단어의 임베딩 차원이 아주 커져 차원의 저주가 발생할 수 있습니다.

[Discrete Representation의 두번째 단점]
One-hot encoding은 단어 간 관계를 파악할 수 없습니다.

매우 유사한 두 문장에서 cat-dog의 관계는 0으로 계산되어 관계를 파악할 수 없게 됩니다.
더 자세한 예시를 들어보면,
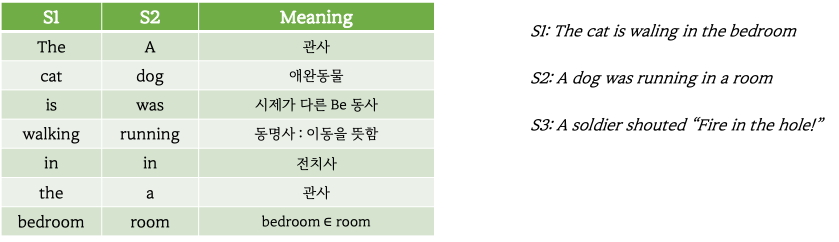
3개의 문장에서 S1과 S2는 매우 유사한 반면 S3은 다른 문맥을 가지고 있는 문장이다. 이 문장들을 16차원의 unigram으로 벡터화 해서 각각의 문장 유사도를 구해보면 one-hot encoding의 단점을 알 수 있습니다.

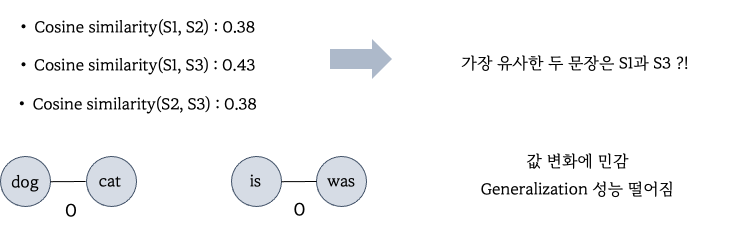
코사인 유사도로 각 단어의 임베딩을 계산한 결과 전혀 관련없는 S1과 S3의 유사도가 가장 높게 나왔고,
또한 유사한 단어인 dog-cat & is-was는 0이 나오게 되면서 단어의 관계를 포착하지 못한 것을 알 수 있습니다.
이산적인 표현이기 때문에 약간의 값 변화에 따라서 의미상 차이가 상당히 클 수 있습니다.
또한 discrete variable은 continuous variable에 비교하여 변화에 민감하기 때문에 generalization 성능 또한 떨어집니다.
그래서!
- 단어 간 관계를 파악할 수 있도록
- 값의 변화에 덜 민감하도록
- 적은 차원에 mapping 함으로써 차원의 저주를 피할 수 있도록
하기 위해 Distributed Representation이 필요합니다.
1-3-2. Distributed Representation
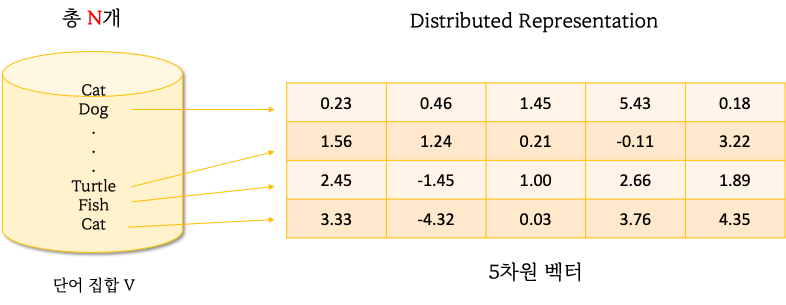
단어집합 V의 개수인 |V| 만큼의 차원으로 임베딩 하지 않아도 되서 차원의 저주를 해결할 수 있고,
Continuous 한 값 덕분에 단어 간 관계도 포착할 수 있습니다.
2. Neural Prabailistic Language Model
이제 본 논문의 핵심 내용입니다.
2-1. Contribution
- 신경망 기반의 Distributed Representation을 사용
- Statistical Language Model에서 발생한 문제를 해결하고자 함

본 논문의 모델은 위의 식을 만족하는 좋은 모델 f를 얻는 것 입니다.
2-2. Model Architecture
- Training Set: 단어 집합 V에 있는 단어들의 시퀀스
- 학습 목적: t-1부터 t-n+1 까지의 단어들을 입력으로 넣었을 때 t번째 단어가 나올 조건부 확률이 높게 나오도록 만드는 것.
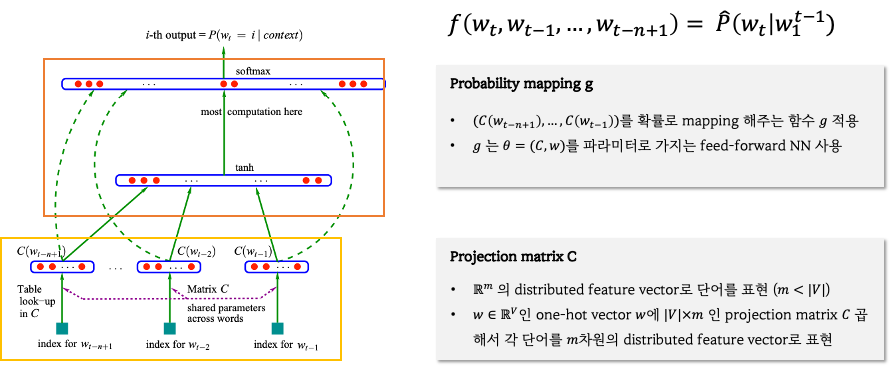
이렇게만 보면 잘 이해가 되지 않아서 관련 자료를 참고해서 이해하였습니다.
먼저 Input 부터 tanh 함수를 거치기 전까지 과정입니다.
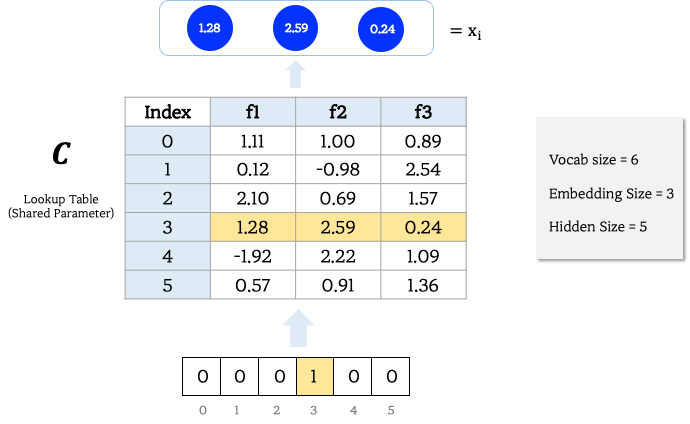
Vocab size는 6이고, Distributed Representation을 위한 Embedding Size가 3이고, Hidden Size가 5일 때 예시 입니다.
- 문장 시퀀스 내 i번째 단어가 단어집합 개수 |V| 만큼 One-hot encoding 된다.
- Shared Parameter 인 Lookup Table의 index를 참조해 Distributed Representation을 얻는다. (Lookup Table C는 학습되는 파라미터 입니다.)
다음, Hidden Layer 단계입니다.
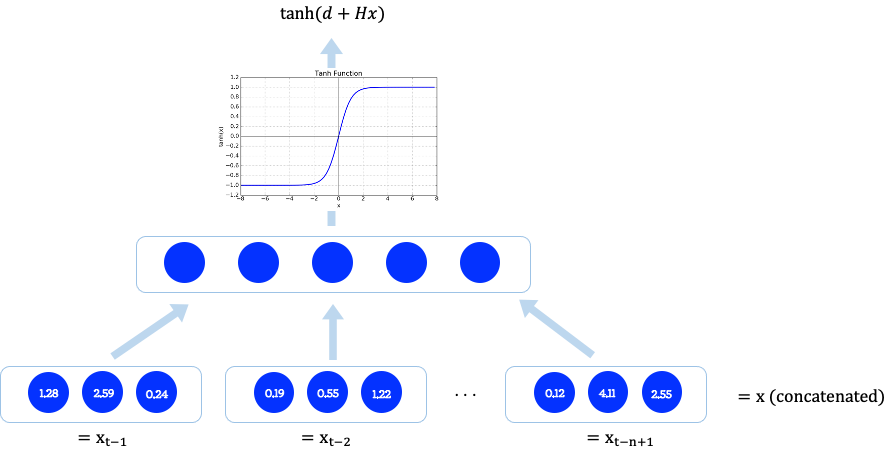
- 문장 시퀀스 속 단어는 각각 Distributed Representation으로 표현된 후에 Concatenation을 거칩니다.
- 연결된 시퀀스는 Hidden size =5 로 표현됩니다.
- 그리고 tanh 함수를 거쳐 H가중치와 bias d를 갖게되는 형식으로 표현됩니다.

이어서,
- 원래 Vocab size로 되돌릴 수 있는 어떤 Layer를 거칩니다.
- 그리고 Hidden Node인 U와 곱해져 logit y를 구하고 이 logit은 Softmax를 거쳐 각 단어에 대한 확률 값으로 표현됩니다. 이 중 가장 높은 확률을 갖는 단어가 다음 단어로 출력됩니다.
마지막으로 점선으로 표현된 부분입니다.
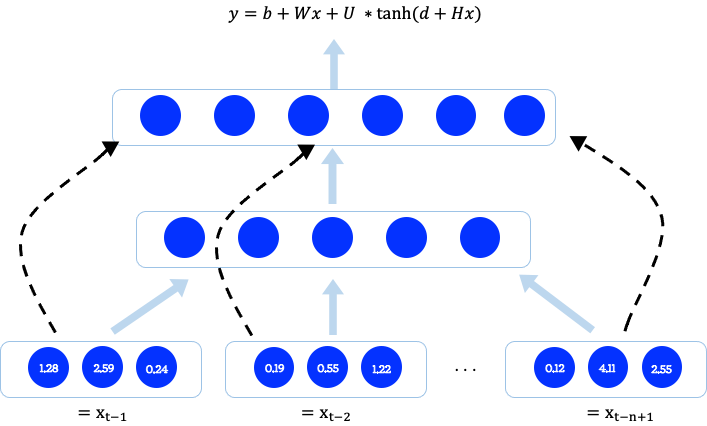
이 부분은 Distributed Representation이 Hidden Layer를 거치지 않고 바로 Softmax로 가는 단계인데요,
왜 실험을 했는지는 논문을 좀 더 살펴봐야 제대로 설명할 수 있을 것 같습니다. 😅
이렇게 해서 모델이 학습해야 하는 파라미터는 다음과 같습니다.

또한 총 파라미터 수는 다음과 같은데요, 식에서 보면 가장 dominant 한 파라미터는 V로, 전체 단어집합에 서로 다른 단어의 개수가 얼마만큼 들어있는지가 파라미터 계산량에 가장 큰 영향을 미치게 됩니다.

최종적으로, 본 논문이 제안한 모델 NNLM은 다음의 Object Function을 가지고 일련의 학습과정을 통하여 Distributed Word Representation Table C를 완성합니다.

3. Experiments
실험은 Perplexcity를 사용하여 NN 모델과 N-gram 모델의 성능을 비교했습니다.
Perplexity가 낮을 수록 문장의 발생 확률이 높아 언어모델이 잘 학습되었음을 의미합니다.

Test에서 MLP(Neural Network)를 사용한 모델이 N-gram based의 다른 모델(Interpolated, back-off)과 비교했을 때, 가장 낮은 Perplexity를 보여주는 것을 확인할 수 있습니다.
그 밖의 더 자세한 실험 내용은 논문에서 확인할 수 있습니다. 자세한 내용은 논문을 다시 보게 될 쯤에 정리해서 올려야겠습니다.
4. Code
논문을 코드로 직접 구현할 수 있다면 얼마나 좋을까요?
아직 저에겐 그런 실력이 없어서 잘 짜여진 코드를 공부하는 것으로 대신해보려고 합니다.
GPU 가속이 있는 pytorch를 사용하여 제안된 NPLM을 구현
코드 설명
Colab notebook
5. Review Paper Question
요즘 진행하고 있는 NLP 논문 스터디에서는 각자 발표한 논문의 내용을 잘 이해했는지 확인할 수 있는 review paper question을 공유하고 있습니다. 논문의 내용을 한번 되짚어보는 좋은 방법인 것 같습니다.
본 논문에서 언급한 Statistical Language Model의 단점은 무엇인가요?
본 논문의 제목이 probabilistic 인 이유를 본 논문 이전의 LM 모델과 비교해 설명해주세요.
본 논문이 제안하는 핵심 내용 2가지가 무엇인가요?
Neural Probabilistic Model에서 objective function은 무엇인가요?
본 논문이 설명하는 shared parameter가 정확히 무엇을 의미하나요?
본 논문은 실험을 위해 metric으로 perplexity를 사용했습니다. Perplexity로 어떻게 성능을 측정할 수 있을까요?
본 논문을 기반으로 나온 Language Model의 방법에는 무엇이 있을까요?
Reference
- 고려대학교 산업경영공학부 DSBA 연구실, "[Paper Review] A Neural Probabilistic Language Model", https://www.youtube.com/watch?v=ycxZORWPPP4 , 2022.08.27
- nlp-masters, "Neural Probabilistic Language Model 신경망 언어 모델", https://www.youtube.com/watch?v=KXzdkOTqVjI, 2022.08.27
- Where the light is, "Machine Learning, Deep Learning-[Paper review] A Neural Probabilistic Language Model", https://nrhan.tistory.com/entry/Paper-review-A-Neural-Probabilistic-Language-Model, 2022.08.27
- Woosung Choi ws-choi, "Paper Review: A Neural Probabilistic Language Model", https://ws-choi.github.io/blog-kor/nlp/deeplearning/paperreview/Paper-Review-A-Neural-Probabilistic-Language-Model/, 2022.08.27
- RISING FASTBALL, "[자연어처리][paper review] NNLM : A Neural Probabilistic Language Model", https://supkoon.tistory.com/16, 2022.08.27
'Machine & Deep Learning > NLP Paper' 카테고리의 다른 글
| Training Compute-Optimal Large Language Models 리뷰 (0) | 2023.09.08 |
|---|---|
| [Paper] Are Large Pre-Trained Language Models Leaking Your Personal Information? (3) | 2023.02.15 |

