
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- paper review
- 프로그래머스
- 코딩테스트
- 코드트리
- Lora
- 그래프이론
- 머신러닝
- 코딩테스트실력진단
- Study
- Generative AI
- LLM
- 파인튜닝
- Scaling Laws
- peft
- Coursera
- Python
- 데이터분석
- DP
- speaking
- bfs/dfs
- 완전탐색
- Fine-Tuning
- English
- 플로이드와샬
- 판다스
- 최단경로
- 알고리즘
- 이분탐색
- 파이썬
- 스터디
Archives
- Today
- Total
생각하는 아져씨
머신러닝 복습, 컬럼을 기준으로 그룹화/집계하기 💪 본문
머신러닝에서 모델의 성능을 높이는데 정제된 데이터, 좋은 알고리즘을 사용하는 것도 있지만 무엇보다도 데이터를 목적에 맞게 추출하고 가공하는 것도 중요하다.
오늘은 데이터를 분석할 때 빈번하게 등장하는 groupby, merge, agg를 사용해서 간단한 문제를 연습해봤다.
Problem.
2개의 데이터 프레임이 있다. '년도' 컬럼을 기준으로 그룹화하여 나라명 개수, 행복기대치의 평균/표준편차/중간값을 구해보자.
정답은 다음의 형태를 띄도록 출력해보자.
정답은 다음의 형태를 띄도록 하시오.
|년도|나라명 개수|mean|std|median|
|---|---|---|---|---|
|내용 1|내용 2|내용 3|내용 4|내용 5|
|내용 5|내용 6|내용 7|내용 8|내용 9|
|내용 9|내용 10|내용 11|내용 12|내용13|
데이터는 블로그를 참고해 활용했다.
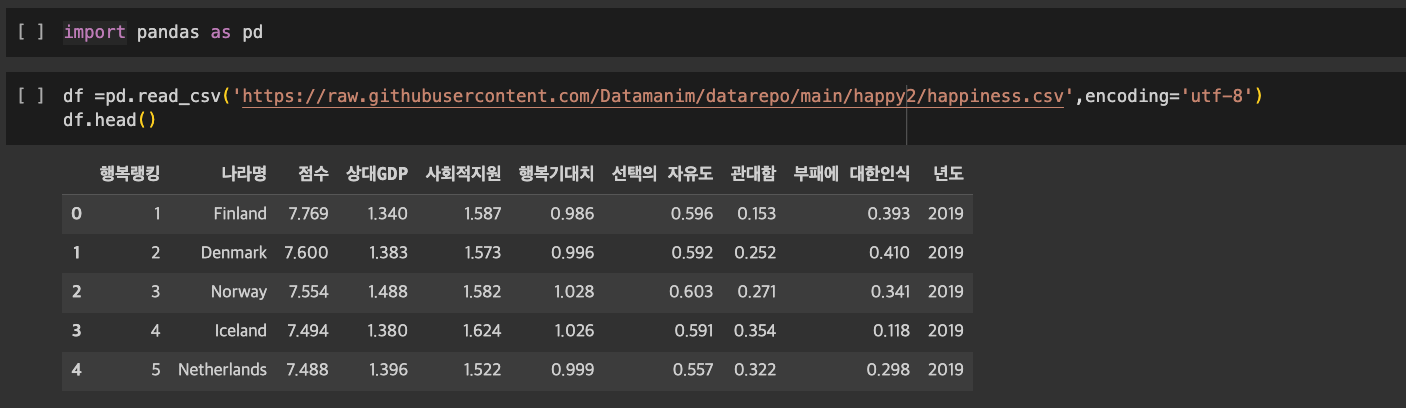
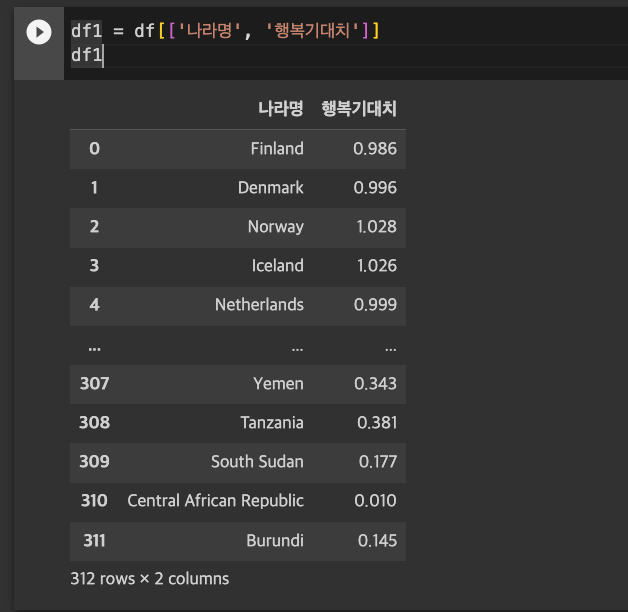
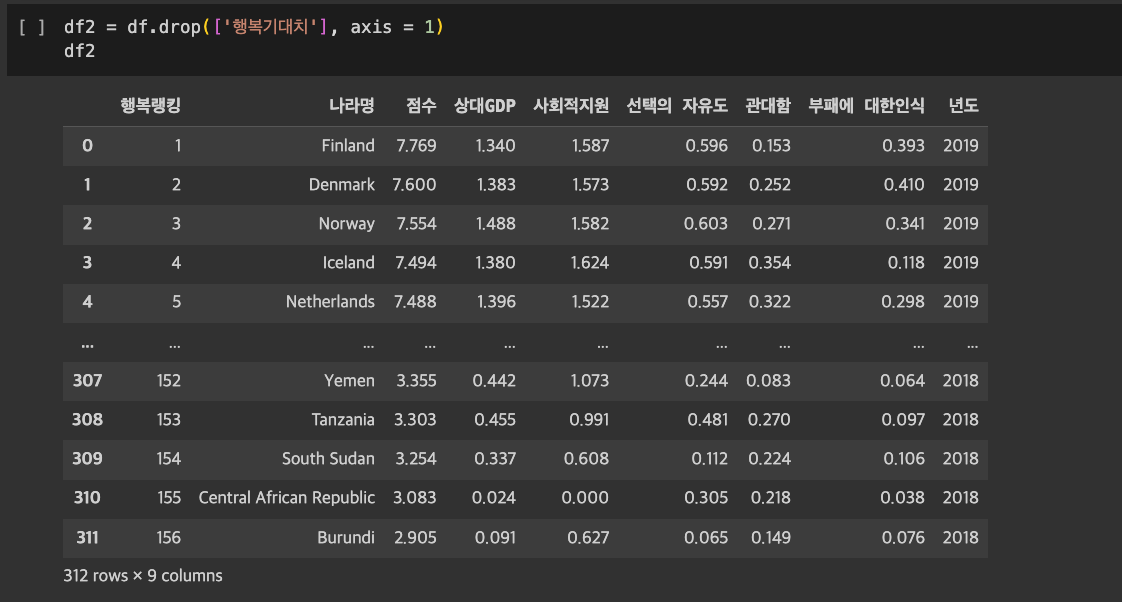
- 오리지널 데이터프레임 : 나라명, 점수, 상대GDP, 사회적지원, 행복기대치, 선택의 자유도, 관대함, 부패에 대한인식, 년도
- 데이터프레임 1 : 나라명, 행복기대치
- 데이터프레임 2 : 나라명, 점수, 상대GDP, 사회적지원, 선택의 자유도, 관대함, 부패에 대한인식, 년도
문제를 풀기 전, 일단 오리지널 데이터프레임에서 데이터프레임1과 2로 나눴다.
풀이순서는 이렇게 정했다.
- df1과 df2를 '나라명' 컬럼 기준으로 병합한다.
- 완성된 데이터프레임을 '년도' 컬럼 기준으로 그룹화한다. -> 나라명 개수, 행복기대치의 평균, 표준편차, 중간값을 구한다.

그룹화하고 나서 각 컬럼에 대해 어떤 집계를 하고 싶을 때 유용한 함수가 있었다.
바로 agg이다.
딕셔너리 형태로 컬럼에 대해 집계하고 싶은 함수를 매핑해주면 된다.

공식 문서를 보면 많은 함수들이 있다.


grouby를 활용하는 방법은 여기를 참고했다.
'Machine & Deep Learning > ML & DL' 카테고리의 다른 글
| 머신러닝 복습, 데이터 스케일링이 뭐냐💪 (0) | 2023.10.19 |
|---|---|
| 머신러닝 복습, 범주형 변수를 인코딩해보자 💪 (1) | 2023.10.19 |
'Machine & Deep Learning/ML & DL' Related Articles
more

