
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- Python
- 그래프이론
- 코드트리
- peft
- speaking
- DP
- Fine-Tuning
- Study
- Lora
- 이분탐색
- 프로그래머스
- LLM
- 스터디
- 최단경로
- paper review
- Scaling Laws
- 완전탐색
- 코딩테스트실력진단
- bfs/dfs
- English
- 데이터분석
- 파인튜닝
- Generative AI
- 플로이드와샬
- 판다스
- 코딩테스트
- Coursera
- 머신러닝
- 알고리즘
- 파이썬
Archives
- Today
- Total
생각하는 아져씨
머신러닝 복습, 데이터 스케일링이 뭐냐💪 본문
Data Scaling?!
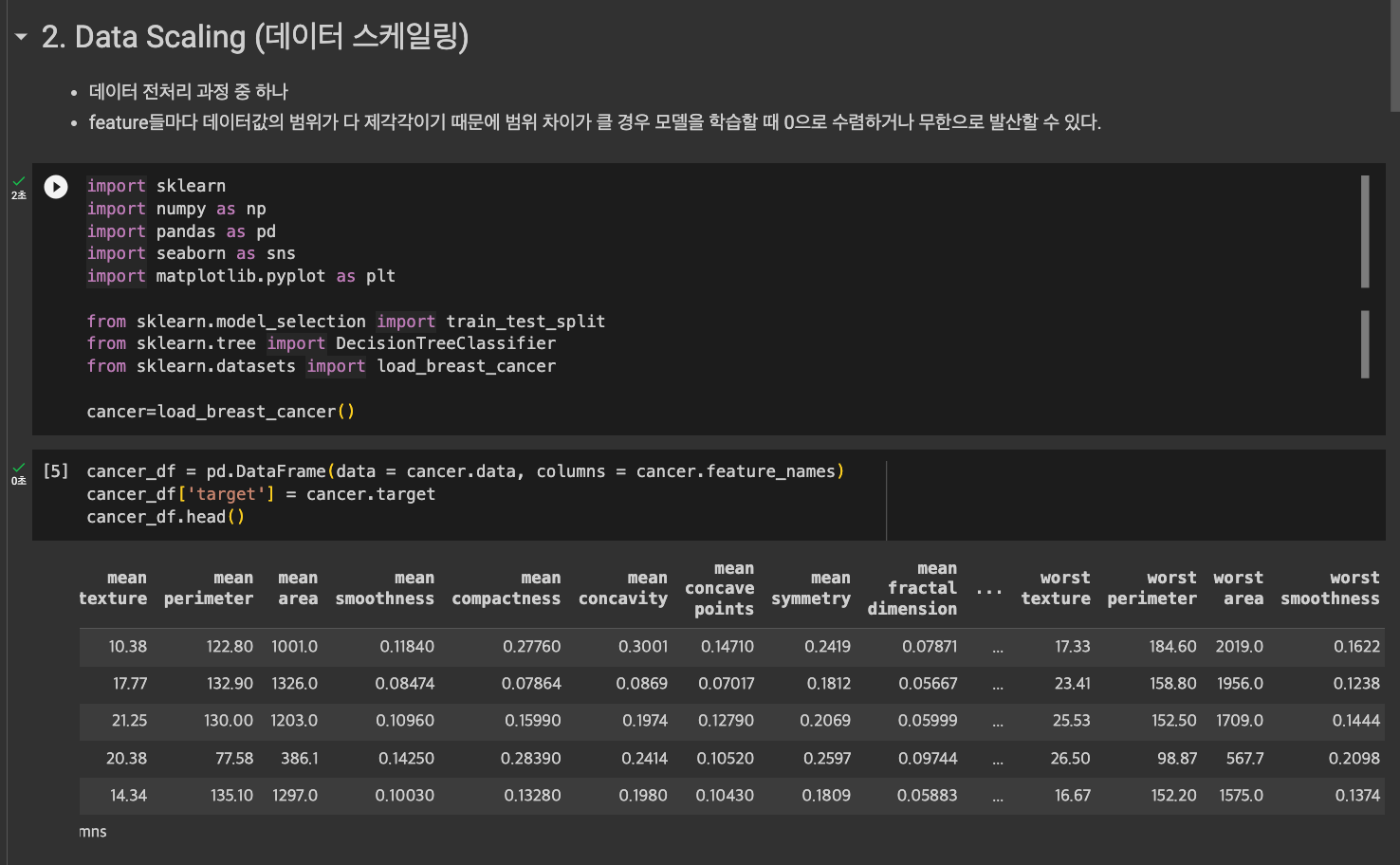
데이터 스케일링은 데이터의 범위와 분포를 조정하는 작업을 의미한다. 이를 통해 모든 특성이 동일한 스케일을 갖게 되며, 모델 학습 과정을 안정화시키고 수렴 속도를 높이며, 이상치의 영향을 줄여 모델의 성능을 개선하는데 도움을 주는 전처리 방법 중 하나이다.
데이터를 분석하다 보면 feature들마다 데이터 값의 범위가 다 제각각임을 볼 수 있다. 만약 범위 차이가 크다면 모델을 학습할 때 0으로 수렴하거나 무한으로 발산할 수 있다는 문제점이 있으므로 데이터 스케일링을 해주는 것이 좋다.
여기를 참고해 총 5가지 데이터 스케일링 방법에 대해 연습했다.
- StandardScaler
- MinMaxScaler
- MaxAbsScaler
- RobustScaler
- Normalizer
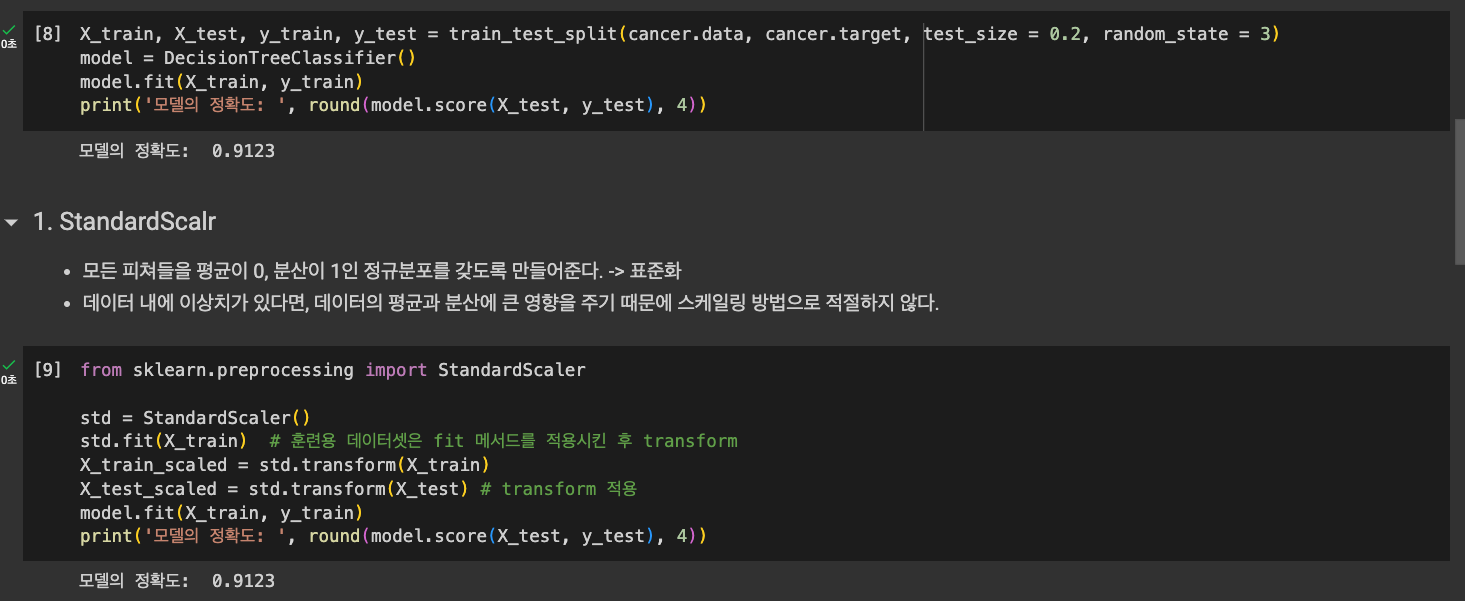


데이터 스케일링을 했을 때 분포가 다름을 확인할 수 있다.




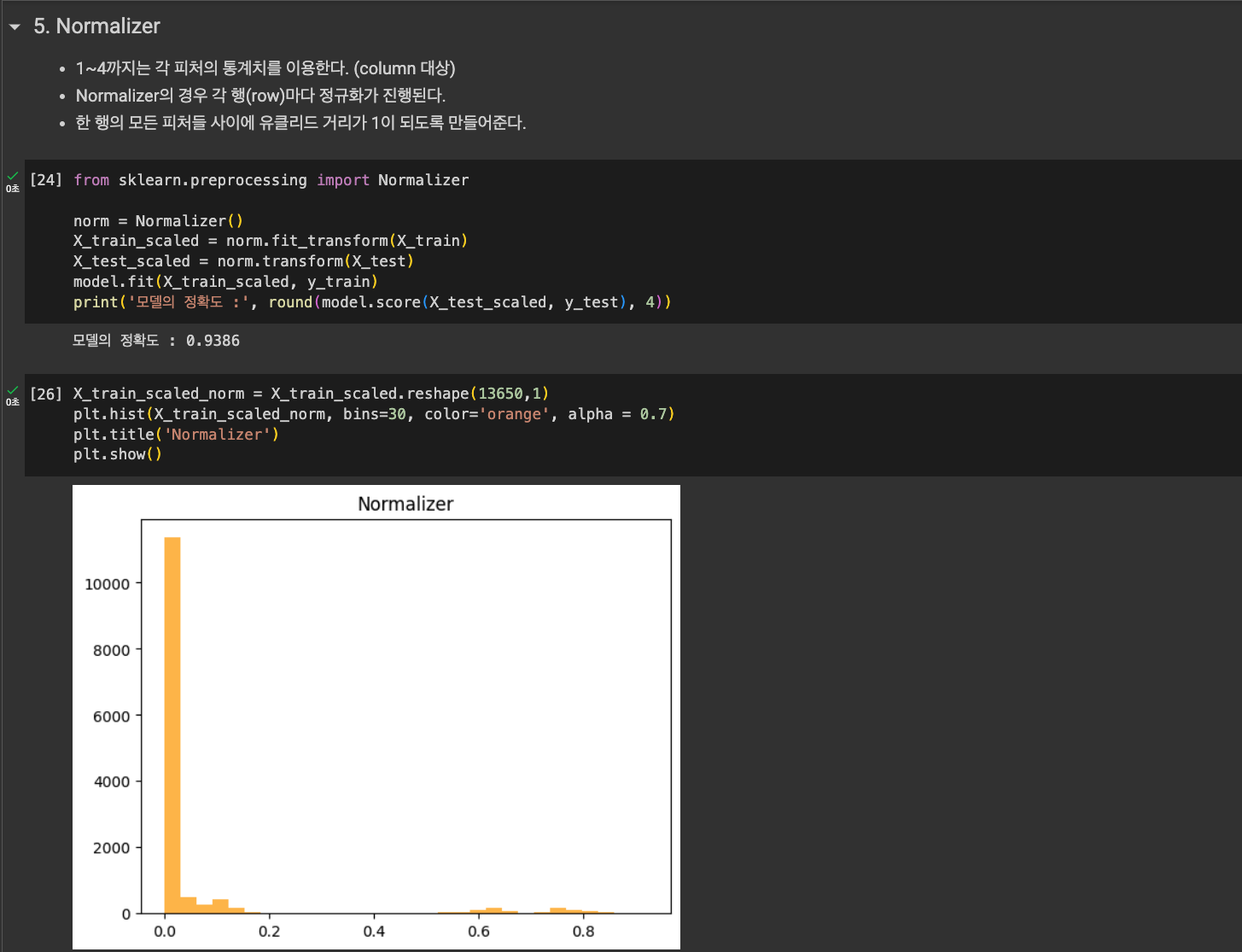
여러 가지 데이터 스케일링을 해보면서 모델의 성능을 살펴봤다.
데이터셋과 알고리즘에 따라 가장 적절한 스케일링 방법이 달라서 그런가 모델의 성능이 달라짐을 확인할 수 있었다.
이점에 유의해서 데이터 스케일링 방법을 선택하면 된다.
'Machine & Deep Learning > ML & DL' 카테고리의 다른 글
| 머신러닝 복습, 범주형 변수를 인코딩해보자 💪 (1) | 2023.10.19 |
|---|---|
| 머신러닝 복습, 컬럼을 기준으로 그룹화/집계하기 💪 (0) | 2023.10.19 |
'Machine & Deep Learning/ML & DL' Related Articles
more

