
개요
오늘은 알고리즘의 가장 첫번째인 누적합과 구현에 대해서 공부한다. 이 글은 세상을 널리 이롭게 하는 돌, 큰 돌 님의 강의를 기반으로 정리하고 개인적으로 공부한 것을 덧붙여 정리하였음을 먼저 밝힌다. 공부를 할 때 마다 새로운 지식을 계속해서 정리할 예정이다.
누적합
누적합이란 요소들의 누적한 합을 의미한다.
어떤 배열을 기반으로 앞에서 부터 요소들의 누적한 합을 저장해서 새로운 배열을 만들고 이를 활용하는 방식이다.
누적합의 종류에는
- prefix sum: 앞에서부터 더하는 것 → 코딩테스트에 나오는 것
- suffix sum: 뒤에서부터 더하는 것
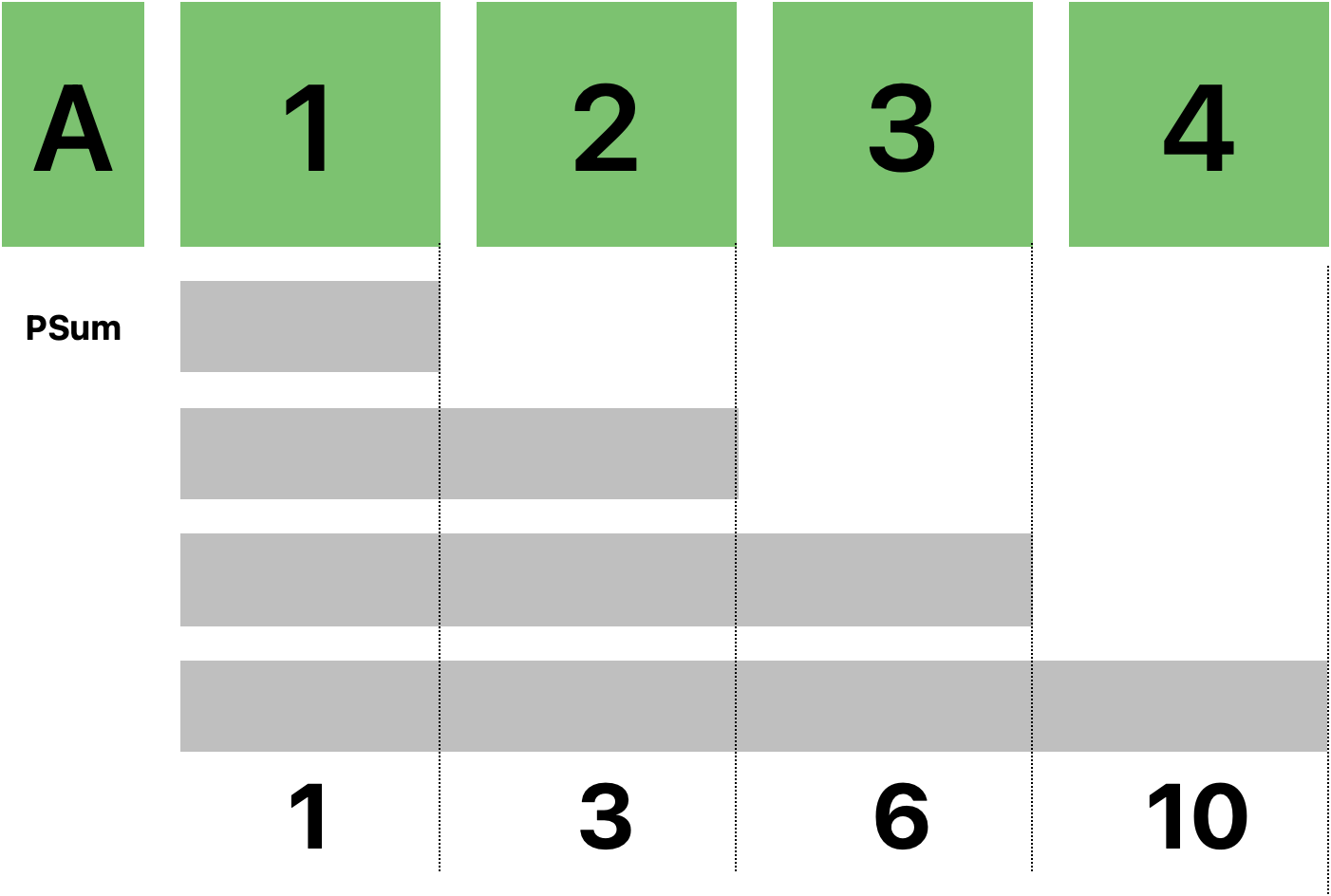
위 그림처럼 누적합이란 누적해서 더해진 값들의 배열을 의미한다.
👉 이런 배열을 미리 만들어놓으면 뭐가 좋을까?
바로 구간 쿼리에 대응하기 쉽다. 0번째 요소부터 3번째 요소까지 다 더한 값을 구하고 싶을 때 A[2]를 가져오면 된다.
누적합 예제 문제 살펴보기
정의는 쉬워보이는데 어떤 문제에서 유용한지를 예제를 통해 살펴보자.
[Naive 한 풀이 방법]
위 문제를 Naive 하게 푼다면 for문 안에서 하나씩 더해간 값을 출력하는 것인데 코드는 다음과 같다.
N, M = map(int, input().split()) # N: 자연수의 개수, M: 합을 구해야 하는 횟수
num = list(map(int, input().split())) # 입력받은 자연수 리스트
for i in range(M): # M번 만큼 합을 구한다.
start, end = map(int, input().split()) # start: 시작 숫자, end: 마침 숫자
sum = 0 # start~end 까지의 합
for j in range(start, end+1):
sum += num[j-1] # 인덱스-1의 값을 가져온다. (배열이니까)
print(sum)- N과 M의 범위가 100,000 임을 기억하자.
- 코드의 시간복잡도는
O(100,000 * 100,000)로 시간 초과가 발생할 수 있다.
- 이럴 때 Naive 한 방법보다는 ‘누적합’을 사용해야 한다.
[누적합을 사용한 풀이 방법]
N, M = map(int, input().split()) # N: 자연수의 개수, M: 합을 구해야 하는 횟수
num = list(map(int, input().split())) # 입력받은 자연수 리스트
p_sum = [0]* (N+1) # 누적합이 담기는 배열, p_sum[1] 부터 누적합이 저장되므로 (N+1) 만큼 할당.
for i in range(N):
p_sum[i+1] = p_sum[i] + num[i]
# print(p_sum) -> [0, 1, 3, 6, 10, 15, 21, 28, 36]
for i in range(M):
start, end = map(int, input().split()) # start: 시작 숫자, end: 마침 숫자
print(p_sum[end] - p_sum[start-1]) # 인덱스 주의: 1~4 까지의 합이라면, 1,2,3,4 의 합이므로 end는 그대로, start는 -1을 해주어야 한다.- 누적합을 저장할 배열
p_sum에 (N+1) 만큼 할당한다. 이 때p_sum[0] = 0이 된다.
- N만큼 돌아서 p_sum 을 만들어 놓고 → O(N)
- 원하는 구간의 합을 구하면 되는데,
p_sum[end] - p_sum[start-1]으로 빠르게 구할 수 있다.
- 이 때 시간 복잡도는,
누적합 배열을 구현 코드의 기본틀은 다음과 같다. 기억해서 활용하자.

2차원 배열에서 누적합
추후에 다시 정리
https://jih3508.tistory.com/50
구현
머릿 속에 떠오르는 아이디어를 소스코드로 바꾸는 과정이다. 어떤 문제든 모든 범위의 코딩 테스트 문제는 구현 문제에 포함된다.
- 보통, 풀이를 떠올리는 것은 쉽지만 소스코드로 옮기기 어려운 문제를 의미한다.
- 알고리즘은 간단한데 코드가 길어지는 문제
- 특정 소수점 자리까지 출력하는 문제
- 문자열을 한 문자 단위로 끊어서 파싱해야 하는 문제
- 완전 탐색, 시뮬레이션은 둘 다 구현이 핵심이 되는 경우가 많다. 추후에 다시 다루도록 한다.
간단한 구현 예제
이처럼 구현을 할 수 있다.
name = 'ahjeong_park'
# Q1
print(name[0:3])
# Q2 - list 변환 후 reverse 함수 사용
name_list = list(name)
name_list.reverse()
name2 = ''.join(name_list)
print(name2)
# Q2 - 문자열 슬라이싱 사용
print(name[::1])
print(name[::2])
print(name[::-1]) # 문자열 거꾸로 나옴
print(name[::-2])
# Q3
print(name + 'ahjeong_park')
'''
ahj
krap_gnoejha
ahjeong_park
ajogpr
krap_gnoejha
ka_neh
ahjeong_parkahjeong_park
'''
구현 시 고려해야 할 메모리 제약 사항 (Python)
- 파이썬에서 리스트 크기
대체로 코딩테스트에서 128 ~ 512MB로 메모리를 제한하기 때문에 수백만 개 이상의 데이터를 처리할 때는 메모리 제한을 염두해야 한다.
데이터 개수(리스트 길이) 메모리 사용량 1,000 약 4KB 1,000,000 약 4MB 10,000,000 약 40MB 크기가 1,000만 이상인 리스트가 있다면 메모리 용량 제한으로 문제를 풀 수 없게 되는 경우도 있다는 점을 기억한다.
- 입출력 소요 시간
- 채점 환경
채점 환경 (Python)
- 파이썬은 c/c++ 보다 동작 속도가 느리다.
- 일반적으로 시간 복잡도가 O(NlogN) 이내의 알고리즘을 사용해 풀어야 한다.
- 알고리즘 문제를 풀 때는 시간제한, 데이터 개수를 먼저 확인하자.
문제를 푸는 방법
알고있지만 놓칠 수 있는 방법이므로 한번 더 떠올리고 문제를 풀어보자.
1.최대, 최소 범위를 파악한다.
2. 단순 구현이라면 구현한다.
3. 무식하게 풀 수 있다면 무식하게 푼다.
4. 아니라면 다른 알고리즘을 생각한다.
5. 제출하기전, 반례를 항상 생각한다.
참조

Uploaded by N2T

